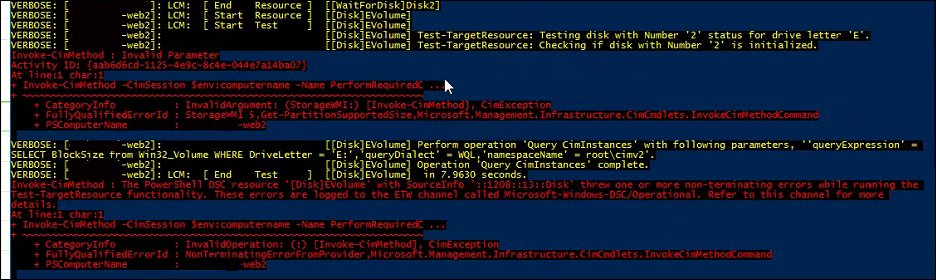
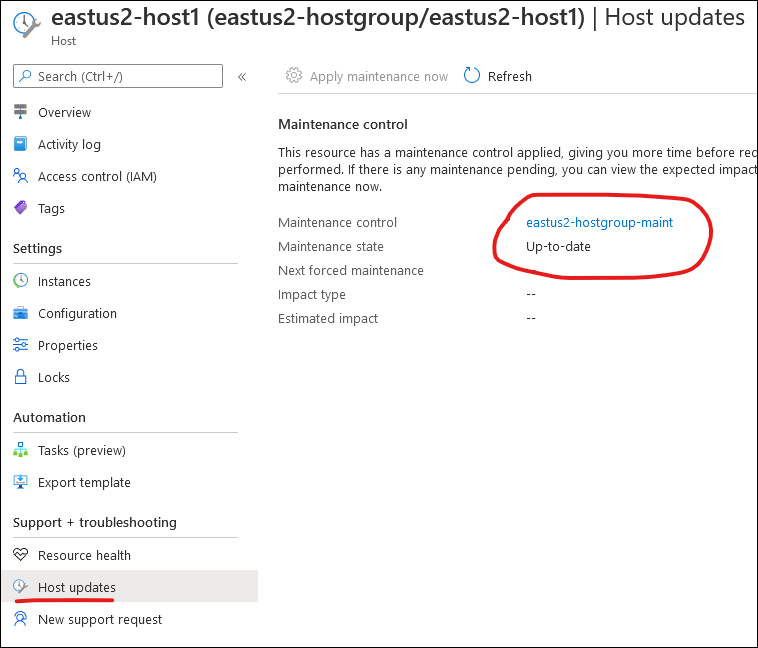
Here’s a bit of a troubleshooting log as I worked through an experimental cluster in Azure Kubernetes Service (AKS).
As a starting point, my cluster was on K8s version 1.21.4, with one node pool of “system” type on Linux, and one nodepool of “user” type on Windows.
I performed an upgrade to 1.22.4, upgrading both the cluster and the nodepools.
Following this I had 2 issues appear in the Azure Portal for my node pools:
- The Linux node pool only rebuilt one of the Virtual Machine Scale Set (VMSS) instances to run 1.22.4 – the other instance was still running 1.21.4 when I viewed the node list in the Portal or with kubectl.
- The Windows node pool displayed a node count of 3, but it also showed “0/0 ready” with NO instances in the node list.
Problem #1 was solved by scaling down the pool to 1 instance, and then scaling back to 2. AKS removed and re-created the VMSS instance properly and it all looked good.
Problem #2 was harder – kubectl didn’t see the nodes at all, but I did find the VMSS with the correct number of instances and they appeared healthy (as far as Virtual Machines go). Performing scaling operations on the node pool through AKS affected the VMSS properly (scaling right down to zero even) however these actions didn’t resolve the problem of kubectl not knowing the nodes existed.
I’m coming into both AKS and Kubernetes pretty blind and ignorant, so I began looking at how I could get onto the Nodes themselves and dig through some logs.
This Microsoft Doc talks about viewing the kubelet logs, using an SSH connection to your nodes through a debug container. However, this didn’t work for me because I didn’t have the original SSH keys from cluster setup, and even though I reset the Windows Node credentials (az aks update –resource-group $RESOURCE_GROUP –name $CLUSTER_NAME –windows-admin-password $NEW_PW) I still received public key errors attempting to SSH.
Instead, I dropped a new VM into the virtual network with a public IP, and gave myself RDP access to this as a jump host. From here, I could perform RDP directly into my Windows Nodes, as well as SMB access to \\nodeIP\c$.
This let me look at this path: c:\k\kubelet.log
Where I found this error:
E1223 15:50:40.001852 4532 server.go:194] "Failed to validate kubelet flags" err="the DynamicKubeletConfig feature gate must be enabled in order to use the --dynamic-config-dir flag"
Exception calling "RunProcess" with "3" argument(s): "Cannot process request because the process (4532) has exited."
At C:\k\kubeletstart.ps1:266 char:1
+ [RunProcess.exec]::RunProcess($exe, $args, [System.Diagnostics.Proces ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [], MethodInvocationException
+ FullyQualifiedErrorId : InvalidOperationException |
E1223 15:50:40.001852 4532 server.go:194] "Failed to validate kubelet flags" err="the DynamicKubeletConfig feature gate must be enabled in order to use the --dynamic-config-dir flag"
Exception calling "RunProcess" with "3" argument(s): "Cannot process request because the process (4532) has exited."
At C:\k\kubeletstart.ps1:266 char:1
+ [RunProcess.exec]::RunProcess($exe, $args, [System.Diagnostics.Proces ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [], MethodInvocationException
+ FullyQualifiedErrorId : InvalidOperationException
I also found errors in the file c:\k\kubeproxy.err.log about missing processes azure-vnet.exe and azure-vnet-ipam.exe.
I did a bunch of reading about Troubleshooting Kubernetes Networking on Windows, and ran “hnsdiag list all” through that process, discovering it had zero entries.
At this point, I spun up a new Windows node pool to use as comparison. Here’s a couple things I found:
- c:\k\config was missing on my broken node
- “hnsdiag list all” produced lots of output on a good node, and virtually empty on my bad node
- The good node had a lot of extra files in C:\k\ related to azure-vnet and azure-vnet-ipam
I began looking into the error listed above, specifically around “the DynamicKubeletConfig feature gate must be enabled”. My searching to this K8s page on dynamic kubelet configuration, stating it as deprecated on 1.22.

Now I wanted to find where that feature flag was coming from.
The Kubelet process runs as a service on these Windows nodes:
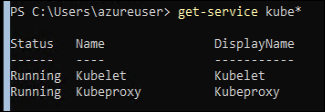
I wanted to see what executable these were actually running, which you can do with this command:
Get-WmiObject win32_service | ?{$_.Name -like '*kube*'} | select Name, DisplayName, State, PathName |
Get-WmiObject win32_service | ?{$_.Name -like '*kube*'} | select Name, DisplayName, State, PathName

Interesting, it is using NSSM. Luckily I’m familiar with that for running Windows services, and you can inspect the config for a service like this:
.\nssm dump kubelet
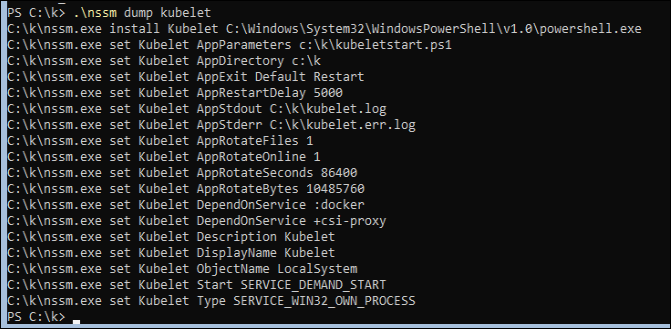
Ok so the Kubelet is a Powershell script: c:\k\kubeletstart.ps1.
I opened that file and started digging. Right away it became apparent where this “DynamicKubeletConfig” flag as an argument on the kubelet service was coming from.
The first line pulls in ClusterConfiguration from a file, and then on line 35 that is turned into $KubeletArgList variable:
# Line 1
$Global:ClusterConfiguration = ConvertFrom-Json ((Get-Content "c:\k\kubeclusterconfig.json" -ErrorAction Stop) | out-string)
# Skip a bunch of stuff until line 35:
$KubeletArgList = $Global:ClusterConfiguration.Kubernetes.Kubelet.ConfigArgs # This is the initial list passed in from aks-engine
dfa |
# Line 1
$Global:ClusterConfiguration = ConvertFrom-Json ((Get-Content "c:\k\kubeclusterconfig.json" -ErrorAction Stop) | out-string)
# Skip a bunch of stuff until line 35:
$KubeletArgList = $Global:ClusterConfiguration.Kubernetes.Kubelet.ConfigArgs # This is the initial list passed in from aks-engine
dfa
I can inspect this PowerShell variable and see the flag added there. Now I compare the C:\k\kubeclusterconfig.json” file between my good and bad nodes, and find that is the only difference between the two!
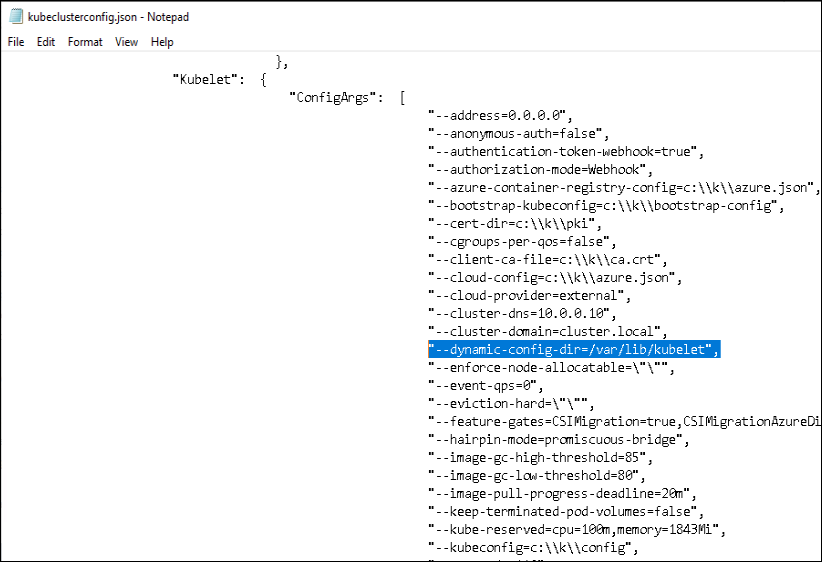
I removed that line and saved the file, and then forced a restart of the Kubelet and KubeProxy services.
It appeared to work! Now kubectl and Azure Portal recognize my node, the C:\k\config file and c:\k\azure-vnet.* files were auto-generated, and my pods started being scheduled properly.
Now my question is, “how come this file didn’t get updated properly to remove the flag, and why did this continue to be an issue every time I scaled a new instance in the VMSS?”.
With 1 working node, I scaled my node pool to a count of 2. What I expected was that the count would recognize as 2 but it would say “1/1 ready” with only a single node still listed from ‘kubectl get nodes’. I am assuming that however this config is stored for the VMSS, editing the file on a single running instance doesn’t update it for all of them.
And that is exactly what happened:

That is the next thread I’ll be pulling on, and will post an update to this when I find out more.
Update – 2022-01-05
I’ve received information from Microsoft Support that this is an internal (non-public) bug of “Nodes failed to register with API server after upgrading to 1.22 AKS version” that the AKS team is working on. However, I’m told that even after a fix has been rolled out; I will need to recreate a new node-pool to resolve this issue – it won’t be back-ported to current node-pools.