This is part 3 in learning about monitoring solutions for an Azure Kubernetes Service (AKS), using Azure Managed Prometheus and Azure Managed Grafana.
- Azure Managed Prometheus and Grafana with Terraform – part 1
- Azure Managed Prometheus and Grafana with Terraform – part 2
- (This Post) Azure Managed Prometheus and Grafana with Terraform – part 3
In this post we are going to use Terraform to finish the implementation of gathering Prometheus metrics for the ingress-nginx controller, which will grant an application-centric view of metrics.
The source code for this part 3 post can be found here in my GitHub repo: aks-prometheus-grafana (part 3)
My criteria for success was to have a populated dashboard in Grafana for ingress-nginx metrics. The source code for ingress-nginx has two different dashboards that can be imported into Grafana: https://github.com/kubernetes/ingress-nginx/tree/main/deploy/grafana/dashboards
Now having access to Azure Managed Grafana, I used the web portal to create an API token that I could pass to Terraform.
Within my Terraform config, I defined a Grafana provider, and then downloaded the JSON files for the dashboards and referenced them as a dashboard resource:
## ---------------------------------------------------
# Grafana Dashboards
## ---------------------------------------------------
provider "grafana" {
url = azurerm_dashboard_grafana.default.endpoint
auth = "securely pass api token"
}
resource "grafana_dashboard" "nginxmetrics" {
depends_on = [ azurerm_dashboard_grafana.default ]
config_json = file("nginx.json")
}
resource "grafana_dashboard" "requestHandlingPerformance" {
depends_on = [ azurerm_dashboard_grafana.default ]
config_json = file("requestHandlingPerformance.json")
}
I could now see these dashboards in my Grafana instance, but they were empty:
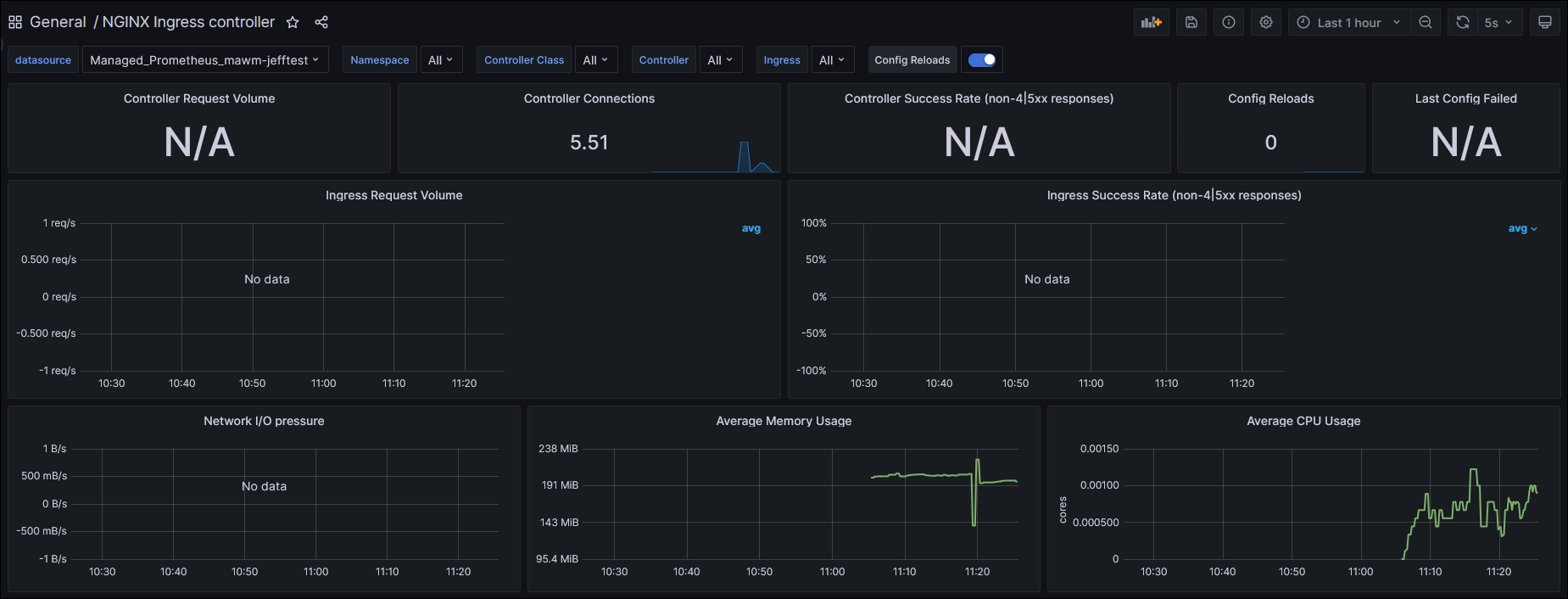
Taking the next step to solve this problem really bogged down based on my lack of understanding of Prometheus and how it is configured. The default installation of Azure Managed Prometheus and Grafana doesn’t do anything with ingress-nginx metrics out of the box, so I began trying to identify how to get it working. Following through Microsoft Docs (which are typically really great) I came across this page: https://learn.microsoft.com/en-us/azure/azure-monitor/essentials/prometheus-metrics-scrape-configuration
This was quite overwhelming to me. Many options are described, none of which I had knowledge about, or had good use cases defined in the doc page for why you would choose one or the other. There is no indication or example of using these patterns either, which doesn’t make for a good starting point.
I looked next at the pod-annotation-based-scraping setting, found within the “ama-metrics-settings-configmap.yaml” file. I set this to include the name of my workload namespace, as well as where I deployed ingress-nginx: podannotationnamespaceregex = "test|ingress-nginx"
After re-running my Terraform and waiting for the metrics pods to reload (judging by the restart count by a kubectl get pods, this didn’t do anything; the dashboards remained blank.
I looked at the Azure Prometheus troubleshooting doc to get the config interface of Prometheus port forwarded, and after reaching this interface in a web browser, I didn’t see any new targets listed beyond the existing node ones.
After some searching and reading, I came across this post: https://medium.com/microsoftazure/automating-managed-prometheus-and-grafana-with-terraform-for-scalable-observability-on-azure-4e5c5409a6b1
It had an example regarding a prometheus scrape config, which was mentioned in the Azure docs. This makes sense, in that what I originally configured above was a scoping statement for where this scrape config would be applied.
This understanding led me to the ingress-nginx docs which have a sample prometheus scrape config!
https://github.com/kubernetes/ingress-nginx/blob/main/deploy/prometheus/prometheus.yaml
Following the Azure doc for prometheus-metric-scrape-configuration, I created a new file named ama-metrics-prometheus-config-configmap.yaml and populated it with the scrape config found within the ingress-nginx repository.
kind: ConfigMap
apiVersion: v1
data:
prometheus-config: |-
global:
scrape_interval: 30s
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
# Scrape only pods with the annotation: prometheus.io/scrape = true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# If prometheus.io/path is specified, scrape this path instead of /metrics
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
# If prometheus.io/port is specified, scrape this port instead of the default
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
# If prometheus.io/scheme is specified, scrape with this scheme instead of http
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
action: replace
regex: (http|https)
target_label: __scheme__
# Include the pod namespace as a label for each metric
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
# Include the pod name as a label for each metric
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
# [Optional] Include all pod labels as labels for each metric
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
metadata:
name: ama-metrics-prometheus-config
namespace: kube-system
I deployed this through Terraform with another kubectl_manifest resource, and then forced traffic to my workloads with a looping Invoke-WebRequest in Powershell.
This succeeded! Very quickly I began to see metrics appear within my Grafana dashboards:
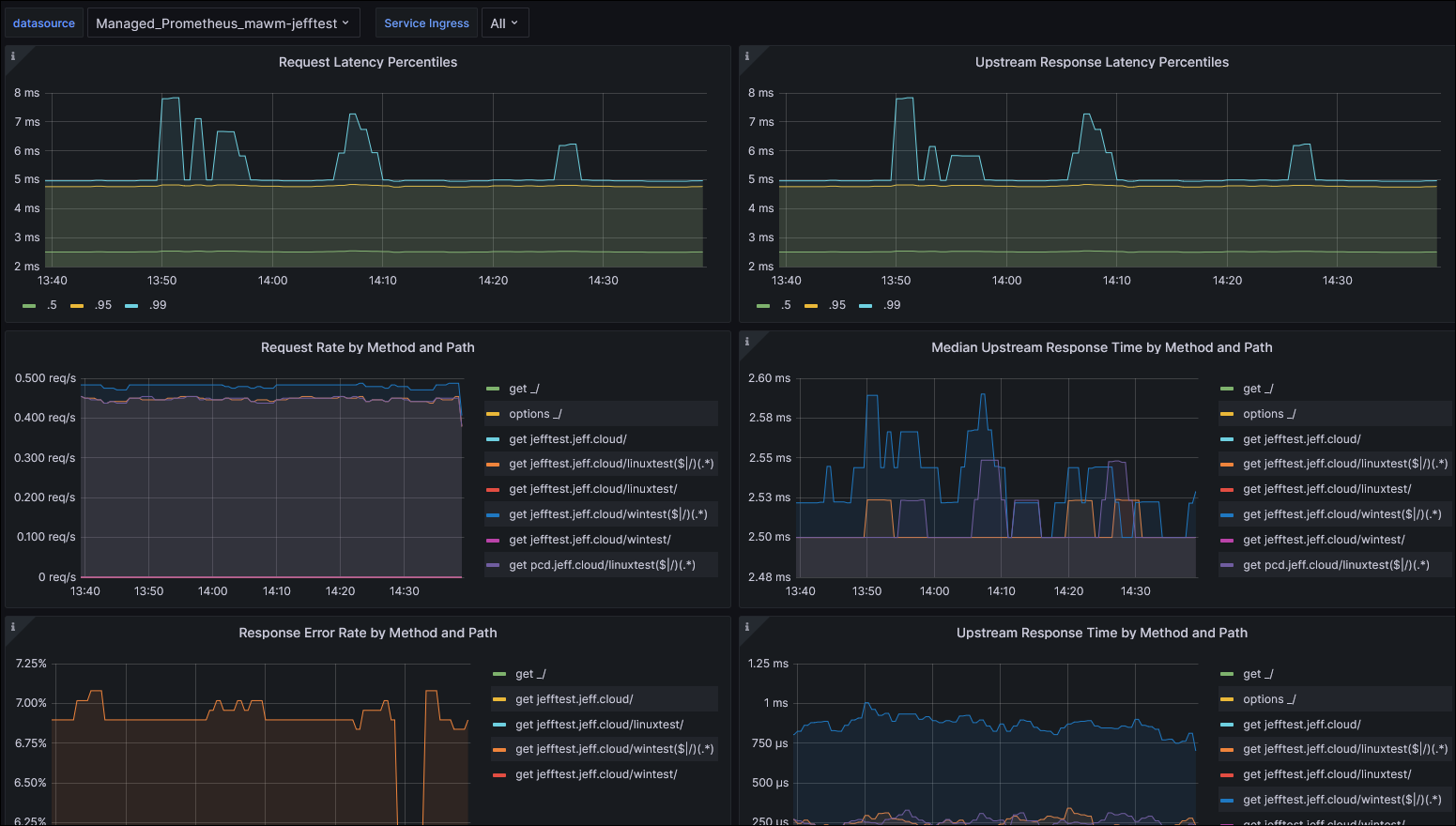
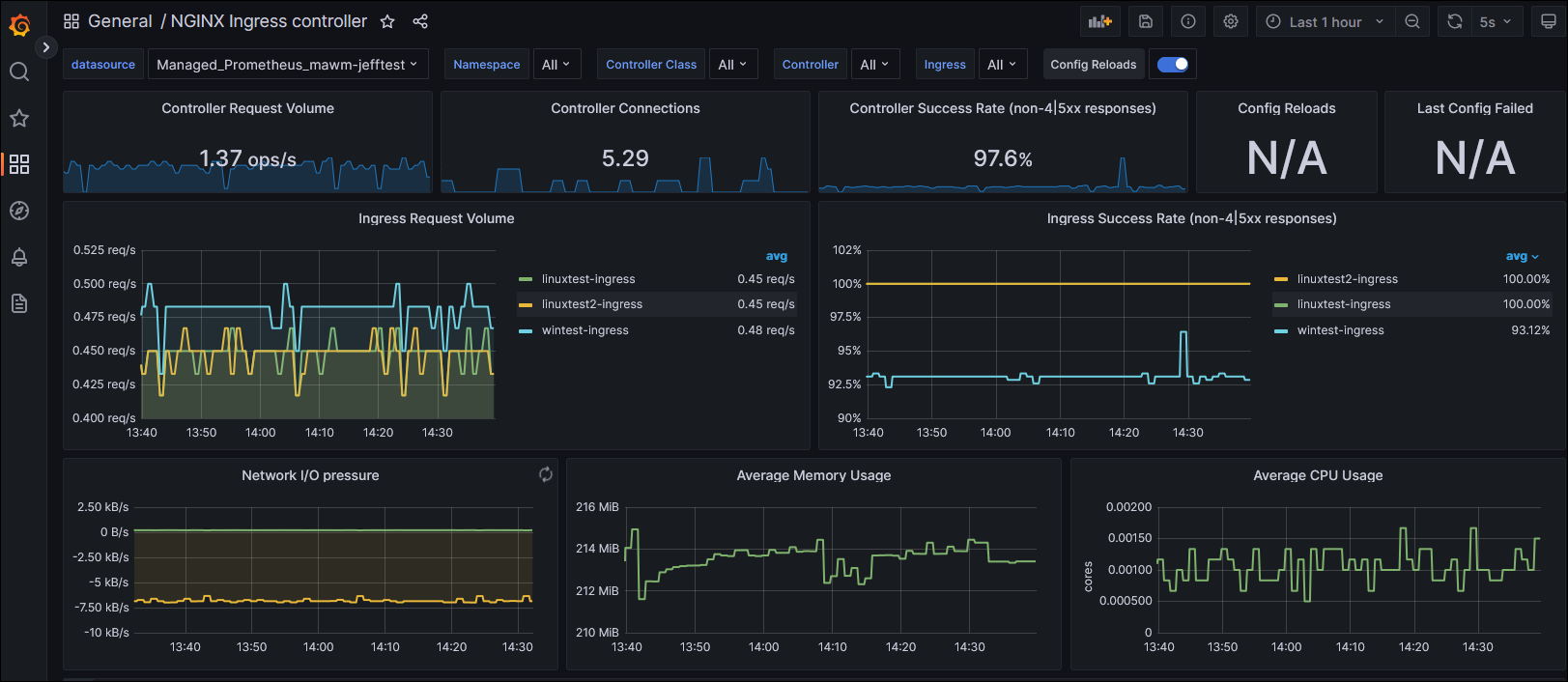
Now when I checked the Prometheus Targets debugging interface, I found an addition for ingress-nginx. You’ll note I also have a “down” entry there for my test workload, which doesn’t have a metrics interface for scraping (but was included in my podannotationnamespaceregex earlier).
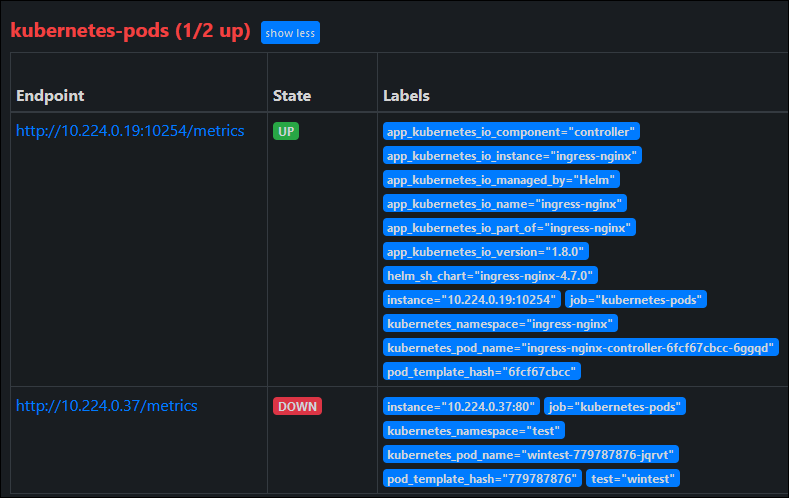
Originally I thought that I was going to encounter namespace boundary problems, because the Monitoring docs for ingress-nginx talk about this limitation when using pod scraping. I thought I would be stuck because I am deploying in separate namespaces which indicates the need to use ServiceMonitor objects; and unfortunately the AKS Metrics add-on very-specifically doesn’t support Prometheus Operator CRDs like ServiceMonitor, so we need to use PodAnnotation scraping.
Fortunately after adding the scrape configuration, there wasn’t any further action that I needed to take, so perhaps the described limitation of Prometheus reaching across namespaces is modified by the default Azure deployment.
I’ll drop a link for one more helpful resource, which uses the Prometheus Operator installation and Service Monitors, but helped me gain some understanding of the components of this system: https://techcommunity.microsoft.com/t5/azure-stack-blog/notes-from-the-field-nginx-ingress-controller-for-production-on/ba-p/3781350
2 thoughts to “Azure Managed Prometheus and Grafana with Terraform – part 3”