This is part 2 in learning about monitoring solutions for an Azure Kubernetes Service (AKS), using Azure Managed Prometheus and Azure Managed Grafana.
- Azure Managed Prometheus and Grafana with Terraform – part 1
- (This Post) Azure Managed Prometheus and Grafana with Terraform – part 2
- Azure Managed Prometheus and Grafana with Terraform – part 3
In this post we are going to use Terraform to configure the Azure Prometheus and Grafana solutions, connect them to our previously created AKS cluster, and look at what metrics we get out of the box.
The source code for this part 2 post can be found here in my GitHub repo: aks-prometheus-grafana (part 2)
Microsoft’s support for deploying a fully integrated solution through infrastructure-as-code is lacking here, in non-obvious ways which I’ll walk through. There is an onboarding guide available, which surprisingly does have example Terraform code; not just Azure CLI commands as I typically see. However, the Terraform examples are still using the AzApi resources for the Prometheus rule groups, despite there existing a Terraform resource for this now in azurerm_monitor_alert_prometheus_rule_group.
I deviate from the code examples because it is using a lot of static string variable references to link the Monitor Workspace (the managed Prometheus resource) with the cluster and Grafana, where I prefer to use Terraform references instead.
We’ll begin by creating our primary resources:
## ---------------------------------------------------
# Managed Prometheus
## ---------------------------------------------------
resource "azurerm_monitor_workspace" "default" {
name = "prom-test"
resource_group_name = azurerm_resource_group.default.name
location = azurerm_resource_group.default.location
}
## ---------------------------------------------------
# Managed Grafana
## ---------------------------------------------------
resource "azurerm_dashboard_grafana" "default" {
name = "graf-test"
resource_group_name = azurerm_resource_group.default.name
location = azurerm_resource_group.default.location
api_key_enabled = true
deterministic_outbound_ip_enabled = false
public_network_access_enabled = true
identity {
type = "SystemAssigned"
}
azure_monitor_workspace_integrations {
resource_id = azurerm_monitor_workspace.default.id
}
}
# Add required role assignment over resource group containing the Azure Monitor Workspace
resource "azurerm_role_assignment" "grafana" {
scope = azurerm_resource_group.default.id
role_definition_name = "Monitoring Reader"
principal_id = azurerm_dashboard_grafana.default.identity[0].principal_id
}
# Add role assignment to Grafana so an admin user can log in
resource "azurerm_role_assignment" "grafana-admin" {
scope = azurerm_dashboard_grafana.default.id
role_definition_name = "Grafana Admin"
principal_id = var.adminGroupObjectIds[0]
}
# Output the grafana url for usability
output "grafana_url" {
value = azurerm_dashboard_grafana.default.endpoint
}
This will tie the Azure Monitor Workspace (effectively, prometheus data store) with Grafana, and automatically include Prometheus as a Grafana data source; after deployment you can see the linked components:
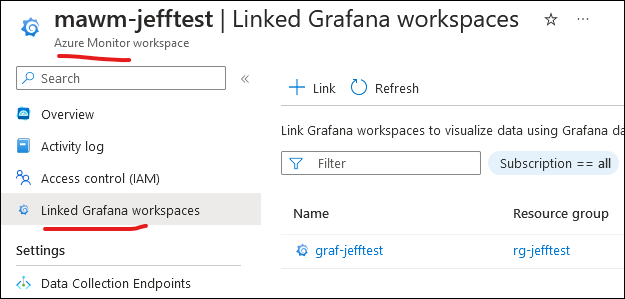
However the code above is only a small portion of what is required to actually connect to the AKS cluster. This is where the Terraform examples from Azure really came in handy, because it outlined the required components, like the section below. Note this includes a large block for the prometheus rule groups, where I have only included the Linux-relevant ones (we’ll get to the Windows integration later).
resource "azurerm_monitor_data_collection_endpoint" "dce" {
name = "MSProm-${azurerm_monitor_workspace.default.location}-${azurerm_kubernetes_cluster.default.name}"
resource_group_name = azurerm_resource_group.default.name
location = azurerm_monitor_workspace.default.location
kind = "Linux"
}
resource "azurerm_monitor_data_collection_rule" "dcr" {
name = "MSProm-${azurerm_monitor_workspace.default.location}-${azurerm_kubernetes_cluster.default.name}"
resource_group_name = azurerm_resource_group.default.name
location = azurerm_monitor_workspace.default.location
data_collection_endpoint_id = azurerm_monitor_data_collection_endpoint.dce.id
kind = "Linux"
destinations {
monitor_account {
monitor_account_id = azurerm_monitor_workspace.default.id
name = "MonitoringAccount1"
}
}
data_flow {
streams = ["Microsoft-PrometheusMetrics"]
destinations = ["MonitoringAccount1"]
}
data_sources {
prometheus_forwarder {
streams = ["Microsoft-PrometheusMetrics"]
name = "PrometheusDataSource"
}
}
description = "DCR for Azure Monitor Metrics Profile (Managed Prometheus)"
depends_on = [
azurerm_monitor_data_collection_endpoint.dce
]
}
resource "azurerm_monitor_data_collection_rule_association" "dcra" {
name = "MSProm-${azurerm_monitor_workspace.default.location}-${azurerm_kubernetes_cluster.default.name}"
target_resource_id = azurerm_kubernetes_cluster.default.id
data_collection_rule_id = azurerm_monitor_data_collection_rule.dcr.id
description = "Association of data collection rule. Deleting this association will break the data collection for this AKS Cluster."
depends_on = [
azurerm_monitor_data_collection_rule.dcr
]
}
resource "azapi_resource" "NodeRecordingRulesRuleGroup" {
type = "Microsoft.AlertsManagement/prometheusRuleGroups@2023-03-01"
name = "NodeRecordingRulesRuleGroup-${azurerm_kubernetes_cluster.default.name}"
location = azurerm_monitor_workspace.default.location
parent_id = azurerm_resource_group.default.id
body = jsonencode({
"properties" : {
"scopes" : [
azurerm_monitor_workspace.default.id
],
"clusterName" : azurerm_kubernetes_cluster.default.name,
"interval" : "PT1M",
"rules" : [
{
"record" : "instance:node_num_cpu:sum",
"expression" : "count without (cpu, mode) ( node_cpu_seconds_total{job=\"node\",mode=\"idle\"})"
},
{
"record" : "instance:node_cpu_utilisation:rate5m",
"expression" : "1 - avg without (cpu) ( sum without (mode) (rate(node_cpu_seconds_total{job=\"node\", mode=~\"idle|iowait|steal\"}[5m])))"
},
{
"record" : "instance:node_load1_per_cpu:ratio",
"expression" : "( node_load1{job=\"node\"}/ instance:node_num_cpu:sum{job=\"node\"})"
},
{
"record" : "instance:node_memory_utilisation:ratio",
"expression" : "1 - ( ( node_memory_MemAvailable_bytes{job=\"node\"} or ( node_memory_Buffers_bytes{job=\"node\"} + node_memory_Cached_bytes{job=\"node\"} + node_memory_MemFree_bytes{job=\"node\"} + node_memory_Slab_bytes{job=\"node\"} ) )/ node_memory_MemTotal_bytes{job=\"node\"})"
},
{
"record" : "instance:node_vmstat_pgmajfault:rate5m",
"expression" : "rate(node_vmstat_pgmajfault{job=\"node\"}[5m])"
},
{
"record" : "instance_device:node_disk_io_time_seconds:rate5m",
"expression" : "rate(node_disk_io_time_seconds_total{job=\"node\", device!=\"\"}[5m])"
},
{
"record" : "instance_device:node_disk_io_time_weighted_seconds:rate5m",
"expression" : "rate(node_disk_io_time_weighted_seconds_total{job=\"node\", device!=\"\"}[5m])"
},
{
"record" : "instance:node_network_receive_bytes_excluding_lo:rate5m",
"expression" : "sum without (device) ( rate(node_network_receive_bytes_total{job=\"node\", device!=\"lo\"}[5m]))"
},
{
"record" : "instance:node_network_transmit_bytes_excluding_lo:rate5m",
"expression" : "sum without (device) ( rate(node_network_transmit_bytes_total{job=\"node\", device!=\"lo\"}[5m]))"
},
{
"record" : "instance:node_network_receive_drop_excluding_lo:rate5m",
"expression" : "sum without (device) ( rate(node_network_receive_drop_total{job=\"node\", device!=\"lo\"}[5m]))"
},
{
"record" : "instance:node_network_transmit_drop_excluding_lo:rate5m",
"expression" : "sum without (device) ( rate(node_network_transmit_drop_total{job=\"node\", device!=\"lo\"}[5m]))"
}
]
}
})
schema_validation_enabled = false
ignore_missing_property = false
}
resource "azapi_resource" "KubernetesReccordingRulesRuleGroup" {
type = "Microsoft.AlertsManagement/prometheusRuleGroups@2023-03-01"
name = "KubernetesReccordingRulesRuleGroup-${azurerm_kubernetes_cluster.default.name}"
location = azurerm_monitor_workspace.default.location
parent_id = azurerm_resource_group.default.id
body = jsonencode({
"properties" : {
"scopes" : [
azurerm_monitor_workspace.default.id
],
"clusterName" : azurerm_kubernetes_cluster.default.name,
"interval" : "PT1M",
"rules" : [
{
"record" : "node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate",
"expression" : "sum by (cluster, namespace, pod, container) ( irate(container_cpu_usage_seconds_total{job=\"cadvisor\", image!=\"\"}[5m])) * on (cluster, namespace, pod) group_left(node) topk by (cluster, namespace, pod) ( 1, max by(cluster, namespace, pod, node) (kube_pod_info{node!=\"\"}))"
},
{
"record" : "node_namespace_pod_container:container_memory_working_set_bytes",
"expression" : "container_memory_working_set_bytes{job=\"cadvisor\", image!=\"\"}* on (namespace, pod) group_left(node) topk by(namespace, pod) (1, max by(namespace, pod, node) (kube_pod_info{node!=\"\"}))"
},
{
"record" : "node_namespace_pod_container:container_memory_rss",
"expression" : "container_memory_rss{job=\"cadvisor\", image!=\"\"}* on (namespace, pod) group_left(node) topk by(namespace, pod) (1, max by(namespace, pod, node) (kube_pod_info{node!=\"\"}))"
},
{
"record" : "node_namespace_pod_container:container_memory_cache",
"expression" : "container_memory_cache{job=\"cadvisor\", image!=\"\"}* on (namespace, pod) group_left(node) topk by(namespace, pod) (1, max by(namespace, pod, node) (kube_pod_info{node!=\"\"}))"
},
{
"record" : "node_namespace_pod_container:container_memory_swap",
"expression" : "container_memory_swap{job=\"cadvisor\", image!=\"\"}* on (namespace, pod) group_left(node) topk by(namespace, pod) (1, max by(namespace, pod, node) (kube_pod_info{node!=\"\"}))"
},
{
"record" : "cluster:namespace:pod_memory:active:kube_pod_container_resource_requests",
"expression" : "kube_pod_container_resource_requests{resource=\"memory\",job=\"kube-state-metrics\"} * on (namespace, pod, cluster)group_left() max by (namespace, pod, cluster) ( (kube_pod_status_phase{phase=~\"Pending|Running\"} == 1))"
},
{
"record" : "namespace_memory:kube_pod_container_resource_requests:sum",
"expression" : "sum by (namespace, cluster) ( sum by (namespace, pod, cluster) ( max by (namespace, pod, container, cluster) ( kube_pod_container_resource_requests{resource=\"memory\",job=\"kube-state-metrics\"} ) * on(namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ( kube_pod_status_phase{phase=~\"Pending|Running\"} == 1 ) ))"
},
{
"record" : "cluster:namespace:pod_cpu:active:kube_pod_container_resource_requests",
"expression" : "kube_pod_container_resource_requests{resource=\"cpu\",job=\"kube-state-metrics\"} * on (namespace, pod, cluster)group_left() max by (namespace, pod, cluster) ( (kube_pod_status_phase{phase=~\"Pending|Running\"} == 1))"
},
{
"record" : "namespace_cpu:kube_pod_container_resource_requests:sum",
"expression" : "sum by (namespace, cluster) ( sum by (namespace, pod, cluster) ( max by (namespace, pod, container, cluster) ( kube_pod_container_resource_requests{resource=\"cpu\",job=\"kube-state-metrics\"} ) * on(namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ( kube_pod_status_phase{phase=~\"Pending|Running\"} == 1 ) ))"
},
{
"record" : "cluster:namespace:pod_memory:active:kube_pod_container_resource_limits",
"expression" : "kube_pod_container_resource_limits{resource=\"memory\",job=\"kube-state-metrics\"} * on (namespace, pod, cluster)group_left() max by (namespace, pod, cluster) ( (kube_pod_status_phase{phase=~\"Pending|Running\"} == 1))"
},
{
"record" : "namespace_memory:kube_pod_container_resource_limits:sum",
"expression" : "sum by (namespace, cluster) ( sum by (namespace, pod, cluster) ( max by (namespace, pod, container, cluster) ( kube_pod_container_resource_limits{resource=\"memory\",job=\"kube-state-metrics\"} ) * on(namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ( kube_pod_status_phase{phase=~\"Pending|Running\"} == 1 ) ))"
},
{
"record" : "cluster:namespace:pod_cpu:active:kube_pod_container_resource_limits",
"expression" : "kube_pod_container_resource_limits{resource=\"cpu\",job=\"kube-state-metrics\"} * on (namespace, pod, cluster)group_left() max by (namespace, pod, cluster) ( (kube_pod_status_phase{phase=~\"Pending|Running\"} == 1) )"
},
{
"record" : "namespace_cpu:kube_pod_container_resource_limits:sum",
"expression" : "sum by (namespace, cluster) ( sum by (namespace, pod, cluster) ( max by (namespace, pod, container, cluster) ( kube_pod_container_resource_limits{resource=\"cpu\",job=\"kube-state-metrics\"} ) * on(namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ( kube_pod_status_phase{phase=~\"Pending|Running\"} == 1 ) ))"
},
{
"record" : "namespace_workload_pod:kube_pod_owner:relabel",
"expression" : "max by (cluster, namespace, workload, pod) ( label_replace( label_replace( kube_pod_owner{job=\"kube-state-metrics\", owner_kind=\"ReplicaSet\"}, \"replicaset\", \"$1\", \"owner_name\", \"(.*)\" ) * on(replicaset, namespace) group_left(owner_name) topk by(replicaset, namespace) ( 1, max by (replicaset, namespace, owner_name) ( kube_replicaset_owner{job=\"kube-state-metrics\"} ) ), \"workload\", \"$1\", \"owner_name\", \"(.*)\" ))",
"labels" : {
"workload_type" : "deployment"
}
},
{
"record" : "namespace_workload_pod:kube_pod_owner:relabel",
"expression" : "max by (cluster, namespace, workload, pod) ( label_replace( kube_pod_owner{job=\"kube-state-metrics\", owner_kind=\"DaemonSet\"}, \"workload\", \"$1\", \"owner_name\", \"(.*)\" ))",
"labels" : {
"workload_type" : "daemonset"
}
},
{
"record" : "namespace_workload_pod:kube_pod_owner:relabel",
"expression" : "max by (cluster, namespace, workload, pod) ( label_replace( kube_pod_owner{job=\"kube-state-metrics\", owner_kind=\"StatefulSet\"}, \"workload\", \"$1\", \"owner_name\", \"(.*)\" ))",
"labels" : {
"workload_type" : "statefulset"
}
},
{
"record" : "namespace_workload_pod:kube_pod_owner:relabel",
"expression" : "max by (cluster, namespace, workload, pod) ( label_replace( kube_pod_owner{job=\"kube-state-metrics\", owner_kind=\"Job\"}, \"workload\", \"$1\", \"owner_name\", \"(.*)\" ))",
"labels" : {
"workload_type" : "job"
}
},
{
"record" : ":node_memory_MemAvailable_bytes:sum",
"expression" : "sum( node_memory_MemAvailable_bytes{job=\"node\"} or ( node_memory_Buffers_bytes{job=\"node\"} + node_memory_Cached_bytes{job=\"node\"} + node_memory_MemFree_bytes{job=\"node\"} + node_memory_Slab_bytes{job=\"node\"} )) by (cluster)"
},
{
"record" : "cluster:node_cpu:ratio_rate5m",
"expression" : "sum(rate(node_cpu_seconds_total{job=\"node\",mode!=\"idle\",mode!=\"iowait\",mode!=\"steal\"}[5m])) by (cluster) /count(sum(node_cpu_seconds_total{job=\"node\"}) by (cluster, instance, cpu)) by (cluster)"
}
]
}
})
schema_validation_enabled = false
ignore_missing_property = false
}
You can see some linking references in this code, particularly the azurerm_monitor_data_collection_rule_association that links to the AKS cluster id.
I deployed this set of code, and expected to see my Azure Monitor Workspace show a connection to the cluster within “Monitored Clusters”, but did not:
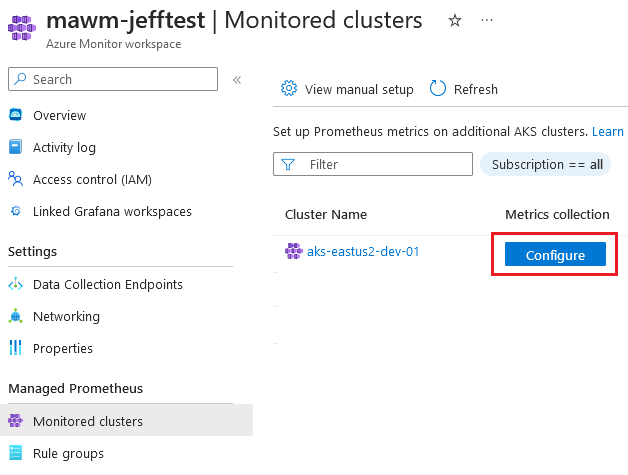
In addition, when evaluating the cluster I didn’t see any Daemonsets created for the ama-metrics-node that the Verify step in the documentation describes.
I pored over the example Terraform code to try and identify what I had missed, and after a while realized that my azurerm_kubernetes_cluster resource was actually different than the example. I was missing the following block, which the provider doc describes as “Specifies a Prometheus add-on profile for the Kubernetes Cluster”.
monitor_metrics {
annotations_allowed = null
labels_allowed = null
}
The example code supplies variables for these two attributes, but I set them to null for now. As soon as I ran a terraform apply my cluster was modified, the Metrics Agent components were deployed to my cluster, and my Grafana dashboards began to be populated.
I hit the Grafana url provided by my Terraform output, signed on as the user that I provided in the var.adminGroupObjectIds, and looked at the built-in Dashboards:
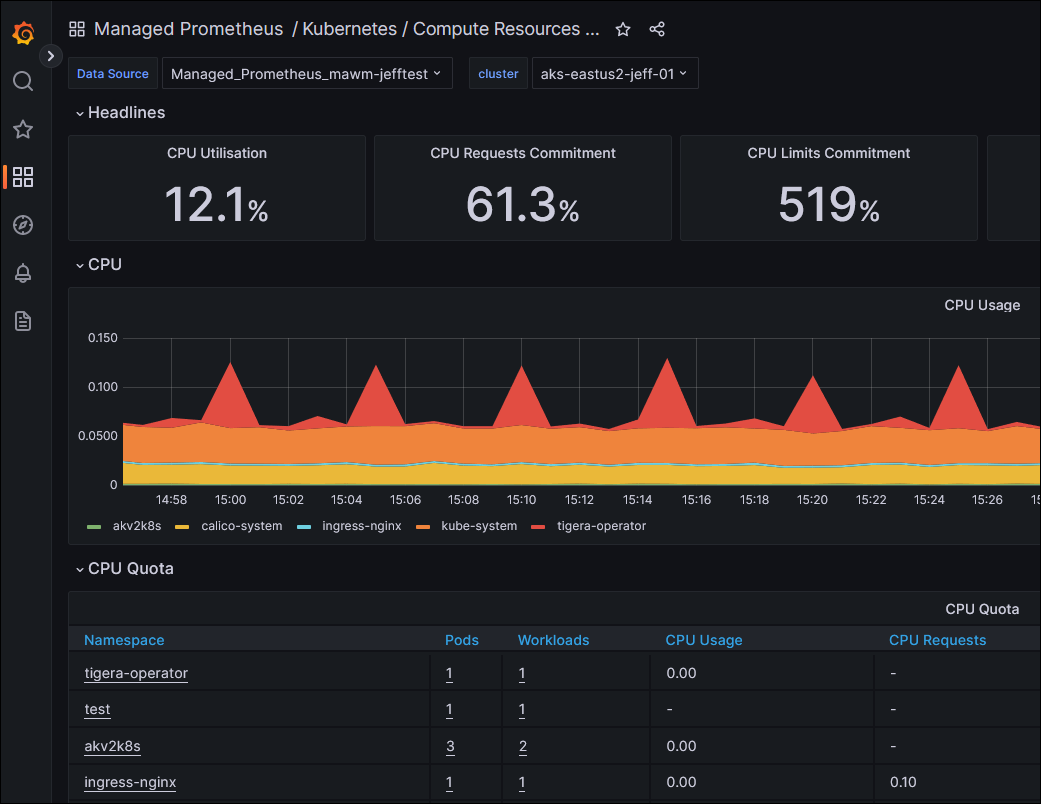
Next I looked to the Windows integration instructions (doc link). These consist of “download this yaml file, and apply it to your cluster with kubectl, which I have integrated into my Terraform deployment.
Step one – download the windows-exporter-daemonset.yaml file, and make some modifications because I’m running Windows Server 2022 nodes.
I changed line 24 to use the LTSC2022 image tag for the InitContainer: mcr.microsoft.com/windows/nanoserver:ltsc2022
I also changed line 31 for the same reason, to this tag: ghcr.io/prometheus-community/windows-exporter:latest-ltsc2022
Then I pulled the ConfigMap resource within that file (separated by the yaml document separator of ---) into it’s own file. This is so that I can use the kubectl_manifest resource from the gavinbunney/kubectl provider to perform the deployment; it doesn’t support multiple yaml documents within a single file. I’m using the kubectl provider for this manifest deployment because kubernetes_manifest has an issue with requiring cluster API availability during the plan, which doesn’t work when we haven’t deployed the cluster yet.
resource "kubectl_manifest" "windows-exporter-daemonset" {
yaml_body = file("windows-exporter-daemonset_daemonset.yaml")
}
resource "kubectl_manifest" "windows-exporter-configmap" {
yaml_body = file("windows-exporter-daemonset_configmap.yaml")
}
With the previous configuration of our kubectl provider in Part 1, this will ensure this Daemonset is deployed to our cluster.
The instructions state to “Apply the ama-metrics-settings-configmap to your cluster” as the next step. This is done in the same way – downloading locally, making the modifications as described (Set the windowsexporter and windowskubeproxy Booleans to true) and adding to our Terraform configuration in another kubernetes_manifest resource:
# Apply the ama-metrics-settings-configmap to your cluster.
resource "kubectl_manifest" "ama-metrics-settings-configmap" {
yaml_body = file("ama-metrics-settings-configmap.yaml")
}
Finally, we need to enable the Prometheus recording rules for Windows nodes and cluster. The doc links to an ARM template, which I could have refactored into an AzApi resource like the Linux recording rules above. However, before I realized that was an option I had already formatted this resource into the Terraform syntax for a monitor_alert_prometheus_rule_group:
resource "azurerm_monitor_alert_prometheus_rule_group" "noderecordingrules" {
# https://github.com/Azure/prometheus-collector/blob/kaveesh/windows_recording_rules/AddonArmTemplate/WindowsRecordingRuleGroupTemplate/WindowsRecordingRules.json
name = "NodeRecordingRulesRuleGroup-Win-${azurerm_kubernetes_cluster.default.name}"
location = azurerm_resource_group.default.location
resource_group_name = azurerm_resource_group.default.name
cluster_name = azurerm_kubernetes_cluster.default.name
description = "Kubernetes Recording Rules RuleGroup for Win"
rule_group_enabled = true
interval = "PT1M"
scopes = [azurerm_monitor_workspace.default.id]
rule {
enabled = true
record = "node:windows_node:sum"
expression = <<EOF
count (windows_system_system_up_time{job="windows-exporter"})
EOF
}
rule {
enabled = true
record = "node:windows_node_num_cpu:sum"
expression = <<EOF
count by (instance) (sum by (instance, core) (windows_cpu_time_total{job="windows-exporter"}))
EOF
}
rule {
enabled = true
record = ":windows_node_cpu_utilisation:avg5m"
expression = <<EOF
1 - avg(rate(windows_cpu_time_total{job="windows-exporter",mode="idle"}[5m]))
EOF
}
rule {
enabled = true
record = "node:windows_node_cpu_utilisation:avg5m"
expression = <<EOF
1 - avg by (instance) (rate(windows_cpu_time_total{job="windows-exporter",mode="idle"}[5m]))
EOF
}
rule {
enabled = true
record = ":windows_node_memory_utilisation:"
expression = <<EOF
1 -sum(windows_memory_available_bytes{job="windows-exporter"})/sum(windows_os_visible_memory_bytes{job="windows-exporter"})
EOF
}
rule {
enabled = true
record = ":windows_node_memory_MemFreeCached_bytes:sum"
expression = <<EOF
sum(windows_memory_available_bytes{job="windows-exporter"} + windows_memory_cache_bytes{job="windows-exporter"})
EOF
}
rule {
enabled = true
record = "node:windows_node_memory_totalCached_bytes:sum"
expression = <<EOF
(windows_memory_cache_bytes{job="windows-exporter"} + windows_memory_modified_page_list_bytes{job="windows-exporter"} + windows_memory_standby_cache_core_bytes{job="windows-exporter"} + windows_memory_standby_cache_normal_priority_bytes{job="windows-exporter"} + windows_memory_standby_cache_reserve_bytes{job="windows-exporter"})
EOF
}
rule {
enabled = true
record = ":windows_node_memory_MemTotal_bytes:sum"
expression = <<EOF
sum(windows_os_visible_memory_bytes{job="windows-exporter"})
EOF
}
rule {
enabled = true
record = "node:windows_node_memory_bytes_available:sum"
expression = <<EOF
sum by (instance) ((windows_memory_available_bytes{job="windows-exporter"}))
EOF
}
rule {
enabled = true
record = "node:windows_node_memory_bytes_total:sum"
expression = <<EOF
sum by (instance) (windows_os_visible_memory_bytes{job="windows-exporter"})
EOF
}
rule {
enabled = true
record = "node:windows_node_memory_utilisation:"
expression = <<EOF
(node:windows_node_memory_bytes_total:sum - node:windows_node_memory_bytes_available:sum) / scalar(sum(node:windows_node_memory_bytes_total:sum))
EOF
}
rule {
enabled = true
record = "node:windows_node_memory_utilisation:"
expression = <<EOF
1 - (node:windows_node_memory_bytes_available:sum / node:windows_node_memory_bytes_total:sum)
EOF
}
rule {
enabled = true
record = "node:windows_node_memory_swap_io_pages:irate"
expression = <<EOF
irate(windows_memory_swap_page_operations_total{job="windows-exporter"}[5m])
EOF
}
rule {
enabled = true
record = ":windows_node_disk_utilisation:avg_irate"
expression = <<EOF
avg(irate(windows_logical_disk_read_seconds_total{job="windows-exporter"}[5m]) + irate(windows_logical_disk_write_seconds_total{job="windows-exporter"}[5m]))
EOF
}
rule {
enabled = true
record = "node:windows_node_disk_utilisation:avg_irate"
expression = <<EOF
avg by (instance) ((irate(windows_logical_disk_read_seconds_total{job="windows-exporter"}[5m]) + irate(windows_logical_disk_write_seconds_total{job="windows-exporter"}[5m])))
EOF
}
}
resource "azurerm_monitor_alert_prometheus_rule_group" "nodeandkubernetesrules" {
# https://github.com/Azure/prometheus-collector/blob/kaveesh/windows_recording_rules/AddonArmTemplate/WindowsRecordingRuleGroupTemplate/WindowsRecordingRules.json
name = "NodeAndKubernetesRecordingRulesRuleGroup-Win-${azurerm_kubernetes_cluster.default.name}"
location = azurerm_resource_group.default.location
resource_group_name = azurerm_resource_group.default.name
cluster_name = azurerm_kubernetes_cluster.default.name
description = "Kubernetes Recording Rules RuleGroup for Win"
rule_group_enabled = true
interval = "PT1M"
scopes = [azurerm_monitor_workspace.default.id]
rule {
enabled = true
record = "node:windows_node_filesystem_usage:"
expression = <<EOF
max by (instance,volume)((windows_logical_disk_size_bytes{job="windows-exporter"} - windows_logical_disk_free_bytes{job="windows-exporter"}) / windows_logical_disk_size_bytes{job="windows-exporter"})
EOF
}
rule {
enabled = true
record = "node:windows_node_filesystem_avail:"
expression = <<EOF
max by (instance, volume) (windows_logical_disk_free_bytes{job="windows-exporter"} / windows_logical_disk_size_bytes{job="windows-exporter"})
EOF
}
rule {
enabled = true
record = ":windows_node_net_utilisation:sum_irate"
expression = <<EOF
sum(irate(windows_net_bytes_total{job="windows-exporter"}[5m]))
EOF
}
rule {
enabled = true
record = "node:windows_node_net_utilisation:sum_irate"
expression = <<EOF
sum by (instance) ((irate(windows_net_bytes_total{job="windows-exporter"}[5m])))
EOF
}
rule {
enabled = true
record = ":windows_node_net_saturation:sum_irate"
expression = <<EOF
sum(irate(windows_net_packets_received_discarded_total{job="windows-exporter"}[5m])) + sum(irate(windows_net_packets_outbound_discarded_total{job="windows-exporter"}[5m]))
EOF
}
rule {
enabled = true
record = "node:windows_node_net_saturation:sum_irate"
expression = <<EOF
sum by (instance) ((irate(windows_net_packets_received_discarded_total{job="windows-exporter"}[5m]) + irate(windows_net_packets_outbound_discarded_total{job="windows-exporter"}[5m])))
EOF
}
rule {
enabled = true
record = "windows_pod_container_available"
expression = <<EOF
windows_container_available{job="windows-exporter"} * on(container_id) group_left(container, pod, namespace) max(kube_pod_container_info{job="kube-state-metrics"}) by(container, container_id, pod, namespace)
EOF
}
rule {
enabled = true
record = "windows_container_total_runtime"
expression = <<EOF
windows_container_cpu_usage_seconds_total{job="windows-exporter"} * on(container_id) group_left(container, pod, namespace) max(kube_pod_container_info{job="kube-state-metrics"}) by(container, container_id, pod, namespace)
EOF
}
rule {
enabled = true
record = "windows_container_memory_usage"
expression = <<EOF
windows_container_memory_usage_commit_bytes{job="windows-exporter"} * on(container_id) group_left(container, pod, namespace) max(kube_pod_container_info{job="kube-state-metrics"}) by(container, container_id, pod, namespace)
EOF
}
rule {
enabled = true
record = "windows_container_private_working_set_usage"
expression = <<EOF
windows_container_memory_usage_private_working_set_bytes{job="windows-exporter"} * on(container_id) group_left(container, pod, namespace) max(kube_pod_container_info{job="kube-state-metrics"}) by(container, container_id, pod, namespace)
EOF
}
rule {
enabled = true
record = "windows_container_network_received_bytes_total"
expression = <<EOF
windows_container_network_receive_bytes_total{job="windows-exporter"} * on(container_id) group_left(container, pod, namespace) max(kube_pod_container_info{job="kube-state-metrics"}) by(container, container_id, pod, namespace)
EOF
}
rule {
enabled = true
record = "windows_container_network_transmitted_bytes_total"
expression = <<EOF
windows_container_network_transmit_bytes_total{job="windows-exporter"} * on(container_id) group_left(container, pod, namespace) max(kube_pod_container_info{job="kube-state-metrics"}) by(container, container_id, pod, namespace)
EOF
}
rule {
enabled = true
record = "kube_pod_windows_container_resource_memory_request"
expression = <<EOF
max by (namespace, pod, container) (kube_pod_container_resource_requests{resource="memory",job="kube-state-metrics"}) * on(container,pod,namespace) (windows_pod_container_available)
EOF
}
rule {
enabled = true
record = "kube_pod_windows_container_resource_memory_limit"
expression = <<EOF
kube_pod_container_resource_limits{resource="memory",job="kube-state-metrics"} * on(container,pod,namespace) (windows_pod_container_available)
EOF
}
rule {
enabled = true
record = "kube_pod_windows_container_resource_cpu_cores_request"
expression = <<EOF
max by (namespace, pod, container) ( kube_pod_container_resource_requests{resource="cpu",job="kube-state-metrics"}) * on(container,pod,namespace) (windows_pod_container_available)
EOF
}
rule {
enabled = true
record = "kube_pod_windows_container_resource_cpu_cores_limit"
expression = <<EOF
kube_pod_container_resource_limits{resource="cpu",job="kube-state-metrics"} * on(container,pod,namespace) (windows_pod_container_available)
EOF
}
rule {
enabled = true
record = "namespace_pod_container:windows_container_cpu_usage_seconds_total:sum_rate"
expression = <<EOF
sum by (namespace, pod, container) (rate(windows_container_total_runtime{}[5m]))
EOF
}
}
This worked! After deploying these changes, when I inspected the Windows-specific Dashboards in Grafana, I began to see data for my Windows workload that I had deployed:
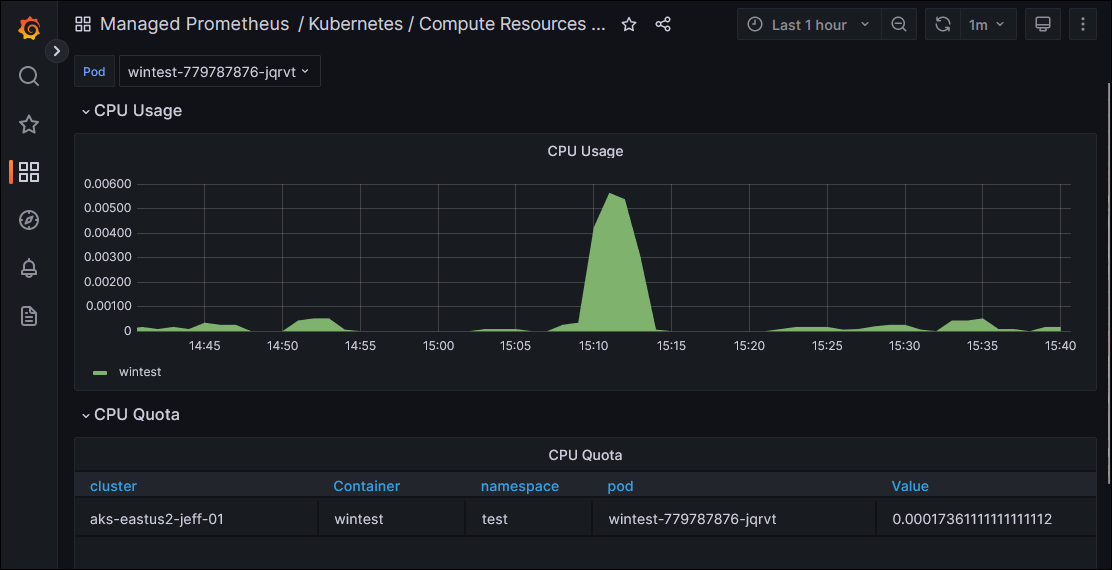
My next goal is to get metrics out of ingress-nginx, which has support for Prometheus metrics. I want to have an easy way to see traffic reaching certain ingress paths without having to instrument each application behind it, so this is a key functionality of my monitoring solution. I’ll look at that more closely in Part 3 of this blog series.
One thought to “Azure Managed Prometheus and Grafana with Terraform – part 2”