I’m learning about monitoring solutions for an Azure Kubernetes Service (AKS), and have been experimenting with Azure Managed Prometheus and Azure Managed Grafana. This is a multi-part blog series due to the length of content:
The Prometheus and Grafana stack is very common for Kubernetes environments, but the idea of not having to maintain the health of those systems is very attractive to me. When I picture integrating these solutions into the platform I’m building, the less complexity I add for my team the easier it is to support the platform.
There are a few key limitations unfortunately that might delay my usage of these solutions:
- Azure Managed Prometheus isn’t currently available in the Azure US Government cloud (link). Expected Q2 2023 (Azure Products by Region | Microsoft Azure)
- Only support for K8s resources, not ingest from standalone VMs and other sources (link). This may be mitigated with extra self-managed Prometheus and Remote-write capabilities
- Role Based Access Control within Managed Grafana isn’t available
One of my key considerations as I evaluated these managed services is how repeatable is implementation through code – I need to be able to reproduce environments on-demand and not depend on written procedures of manual intervention in Portal interfaces.
This Part 1 of the series will cover an initial setup of an environment to facilitate the proof of concept. I’m using Terraform as my deployment tool, running interactively against a local state file for convenience. Relying upon the Terraform providers for AzureRM, Kubernetes, and Helm, I am able to repeatably deploy this solution.
I will say that the methods I use in the following code are only suitable for proof-of-concept environments; there are much better ways to handle secret management and authentication for these providers when targeting a production system; this may include wrapper scripts to pull secrets interactively from a KeyVault, or using Azure Managed Identities for virtual machine resources and ensure Terraform runs from within that resource.
The source code for this part 1 post can be found here in my GitHub repo: aks-prometheus-grafana (part 1)
There are some opinionated resources and structures in what I’m configuring, based on ease-of-use, supporting systems, and integration in the broader platform that I’m building. These will be described throughout this post, and can be easily stripped out if they are unnecessary in other environments.
We begin by specifying required_providers, including the fully qualified address, as this is Terraform best practice (link). Normally I would also include version pinning on these providers in my root module.
terraform {
# ---------------------------------------------------
# Setup providers
# ---------------------------------------------------
required_providers {
azurerm = {
source = "registry.terraform.io/hashicorp/azurerm"
}
kubernetes = {
source = "registry.terraform.io/hashicorp/kubernetes"
}
# Used to deploy kubectl_manifest resource
kubectl = {
source = "gavinbunney/kubectl"
}
helm = {
source = "registry.terraform.io/hashicorp/helm"
}
random = {
source = "registry.terraform.io/hashicorp/random"
}
}
}
Next we’ll specify the Provider Configuration for each:
provider "azurerm" {
features {}
environment = "public"
}
provider "kubernetes" {
host = azurerm_kubernetes_cluster.default.kube_admin_config.0.host
username = azurerm_kubernetes_cluster.default.kube_admin_config.0.username
password = azurerm_kubernetes_cluster.default.kube_admin_config.0.password
client_certificate = base64decode(azurerm_kubernetes_cluster.default.kube_admin_config.0.client_certificate)
client_key = base64decode(azurerm_kubernetes_cluster.default.kube_admin_config.0.client_key)
cluster_ca_certificate = base64decode(azurerm_kubernetes_cluster.default.kube_admin_config.0.cluster_ca_certificate)
}
provider "kubectl" {
host = azurerm_kubernetes_cluster.default.kube_admin_config.0.host
username = azurerm_kubernetes_cluster.default.kube_admin_config.0.username
password = azurerm_kubernetes_cluster.default.kube_admin_config.0.password
client_certificate = base64decode(azurerm_kubernetes_cluster.default.kube_admin_config.0.client_certificate)
client_key = base64decode(azurerm_kubernetes_cluster.default.kube_admin_config.0.client_key)
cluster_ca_certificate = base64decode(azurerm_kubernetes_cluster.default.kube_admin_config.0.cluster_ca_certificate)
}
provider "helm" {
kubernetes {
host = azurerm_kubernetes_cluster.default.kube_admin_config.0.host
username = azurerm_kubernetes_cluster.default.kube_admin_config.0.username
password = azurerm_kubernetes_cluster.default.kube_admin_config.0.password
client_certificate = base64decode(azurerm_kubernetes_cluster.default.kube_admin_config.0.client_certificate)
client_key = base64decode(azurerm_kubernetes_cluster.default.kube_admin_config.0.client_key)
cluster_ca_certificate = base64decode(azurerm_kubernetes_cluster.default.kube_admin_config.0.cluster_ca_certificate)
}
registry {
# Manually perform a `helm repo update` on the runner before running Terraform
url = "oci://artifacts.private.registry"
username = "api"
# Pass in secret on environment variable named TF_VAR_artifactAPIToken
password = var.artifactAPIToken
}
}
Some key things to note from that code block above:
- I’m using the defaults of the AzureRM provider to rely upon my authenticated session with Azure CLI – including the definition of an Azure Subscription to target.
- The Kubernetes and Helm provider configurations are dependent on an “azurerm_kubernetes_cluster” resource that has yet to be defined in my configuration. This is a common (but not great way) to authenticate. A better choice would be to securely build a Kubeconfig on the worker that is to run Terraform, and reference that with the “config_path” attribute instead
- I’m using a private registry for my Helm charts, where my organization has control over versions, content, and security scanning. This is authenticated using an API token that only contains read access, which I am passing in as an OS environment variable in the supported Terraform format.
Let’s create a few initial resources now:
variable "adminGroupObjectIds" {
type = list(string)
description = "A list of Object IDs of Azure Active Directory Groups which should have Admin Role on the Cluster"
default = []
}
variable "artifactAPIToken" {
type = string
description = "String containing API token for private artifact registry"
}
## ---------------------------------------------------
# Initial resource group
## ---------------------------------------------------
# Utilize the current Azure CLI context as a data source for future reference
data "azurerm_client_config" "current" {}
resource "azurerm_resource_group" "default" {
name = "rg-test"
location = "eastus2"
}
## ---------------------------------------------------
# user name and password setup for AKS node pools
## ---------------------------------------------------
resource "random_string" "userName" {
length = 8
special = false
upper = false
}
resource "random_password" "userPasswd" {
length = 32
special = true
override_special = "!#$%&*()-_=+[]{}<>:?"
}
## ---------------------------------------------------
# Azure KeyVault and components
## ---------------------------------------------------
resource "azurerm_key_vault" "default" {
name = "kv-aks1234" # Must resolve to 24 characters or less
resource_group_name = azurerm_resource_group.default.name
location = azurerm_resource_group.default.location
tenant_id = data.azurerm_client_config.current.tenant_id
soft_delete_retention_days = 7
enabled_for_deployment = true
enabled_for_template_deployment = true
sku_name = "standard"
}
# Store the generated username/password in the KeyVault
resource "azurerm_key_vault_secret" "node_admin_name" {
name = "aksadminname"
value = random_string.userName.result
key_vault_id = azurerm_key_vault.default.id
}
resource "azurerm_key_vault_secret" "node_admin_passwd" {
name = "aksadminpasswd"
value = random_password.userPasswd.result
key_vault_id = azurerm_key_vault.default.id
}
This config provides the capability to access the randomly generated username/password for the AKS nodes if required for troubleshooting without having to inspect the Terraform state file to get their values. Note, the KeyVault name must be globally unique.
Time to create the AKS cluster itself, including a Windows node pool because that is part of my environment:
resource "azurerm_kubernetes_cluster" "default" {
name = "aks-eastus2-test"
resource_group_name = azurerm_resource_group.default.name
location = azurerm_resource_group.default.location
dns_prefix = azurerm_resource_group.default.name
node_resource_group = "rg-aks-eastus2-test_node"
public_network_access_enabled = true
azure_active_directory_role_based_access_control {
managed = true
azure_rbac_enabled = true
# Grant Cluster Admin to AzureAD object ids supplied at runtime
admin_group_object_ids = var.adminGroupObjectIds
}
key_vault_secrets_provider {
secret_rotation_enabled = true
secret_rotation_interval = "2m"
}
network_profile {
network_plugin = "azure"
network_mode = "transparent"
network_policy = "calico"
}
default_node_pool {
name = "system"
node_count = 1
vm_size = "Standard_B2ms"
os_sku = "Mariner"
}
windows_profile {
admin_username = random_string.userName.result
admin_password = random_password.userPasswd.result
}
identity {
type = "SystemAssigned"
}
}
resource "azurerm_kubernetes_cluster_node_pool" "default" {
name = "win22"
kubernetes_cluster_id = azurerm_kubernetes_cluster.default.id
mode = "User" # Node Pool Type
enable_node_public_ip = false
enable_auto_scaling = true
node_count = 1
min_count = 1
max_count = 5
max_pods = 10
vm_size = "Standard_B2ms"
os_type = "Windows"
os_sku = "Windows2022"
}
This config creates a cluster with Azure RBAC for Kubernetes enabled (the azure_active_directory_role_based_access_control block), integration with the CSI Secrets Store Driver for KeyVault integration (the key_vault_secrets_provider block) and a System-Assigned Managed Identity (the identity block).
Now a few final components in preparation of the cluster:
resource "azurerm_role_assignment" "clusteradmin-rbacclusteradmin" {
scope = azurerm_kubernetes_cluster.default.id
role_definition_name = "Azure Kubernetes Service RBAC Cluster Admin"
principal_id = var.adminGroupObjectIds[0]
}
## ---------------------------------------------------
# Keyvault access policy for secrets providers
## ---------------------------------------------------
resource "azurerm_key_vault_access_policy" "akvp" {
key_vault_id = azurerm_key_vault.default.id
tenant_id = data.azurerm_client_config.current.tenant_id
object_id = azurerm_kubernetes_cluster.default.key_vault_secrets_provider.0.secret_identity.0.object_id
secret_permissions = [
"Get"
]
}
resource "azurerm_key_vault_access_policy" "akv2k8s" {
key_vault_id = azurerm_key_vault.default.id
tenant_id = data.azurerm_client_config.current.tenant_id
object_id = azurerm_kubernetes_cluster.default.kubelet_identity[0].object_id
secret_permissions = [
"Get"
]
}
We create a role assignment within the Cluster (as part of the Azure RBAC for Kubernetes) based on a user/group object id, and then 2 KeyVault access policies.
The first is for the Azure KeyVault integration using the managed identity that is created when enabling the csi-secrets-store-driver.
The second is created for the managed identity assigned to the Linux nodes which will be used by the Akv2K8s project when installed. In my environment I am using the native Azure KeyVault integration for Windows pods, but the Akv2k8s solution for Linux pods because it offers enhanced security by injecting secrets from a KeyVault into an environment variable only accessible by the running process of the pod itself. This is greater protection than storing the secret as a K8s secret which is retrievable inside the cluster with enough permissions.
Next I’m going to perform Helm installations of a couple charts to assist in making workloads run-able:
## ---------------------------------------------------
# Helm Install
## ---------------------------------------------------
resource "helm_release" "akv2k8s" {
name = "akv2k8s"
chart = "third-party-helm/akv2k8s"
namespace = "akv2k8s"
version = "2.3.2"
create_namespace = true
dependency_update = true
set {
name = "controller.nodeSelector.kubernetes\\.io/os"
value = "linux"
}
set {
name = "env_injector.nodeSelector.kubernetes\\.io/os"
value = "linux"
}
set {
name = "global.metrics.enabled"
value = "true"
}
}
resource "helm_release" "ingress-nginx" {
name = "ingress-nginx"
chart = "third-party-helm/ingress-nginx"
namespace = "ingress-nginx"
version = "4.7.0"
create_namespace = true
dependency_update = true
set {
name = "controller.nodeSelector.kubernetes\\.io/os"
value = "linux"
}
set {
name = "controller.service.annotations.service\\.beta\\.kubernetes\\.io/azure-load-balancer-health-probe-request-path"
value = "/healthz"
}
set {
name = "metrics.enabled"
value = "true"
}
set {
name = "controller.podAnnotations.prometheus\\.io/scrape"
value = "true"
}
#set {
# name = "controller.podAnnotations.prometheus\\.io/port"
# value = "10254"
#}
}
Because I only have one Helm provider registered with a registry block, these chart sources are pulling through a feed on my private registry.
Since I have both Windows and Linux node pools, I need to set the nodeSelector attributes properly otherwise a Linux container will attempt and fail to run on a Windows node. I’m using the azure-load-balancer-health-probe-request-path annotation on ingress-nginx based on the examples provided in Microsoft Docs.
Finally we want to deploy a Windows workload into the cluster for testing and evaluation:
## ---------------------------------------------------
# Sample workload installation
## ---------------------------------------------------
resource "kubernetes_namespace" "test" {
metadata {
name = "test"
labels = {
# Used for akv2k8s integration
"azure-key-vault-env-injection" = "enabled"
}
}
}
resource "kubernetes_deployment_v1" "wintest" {
metadata {
namespace = "test"
name = "wintest"
labels = {
test = "wintest"
}
}
spec {
replicas = 1
selector {
match_labels = {
test = "wintest"
}
}
template {
metadata {
labels = {
test = "wintest"
}
}
spec {
container {
image = "mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2022"
name = "wintest"
}
}
}
}
}
resource "kubernetes_service_v1" "wintest" {
metadata {
namespace = "test"
name = "wintest-svc"
}
spec {
selector = {
test = "wintest"
}
port {
port = 80
target_port = 80
}
}
}
resource "kubernetes_ingress_v1" "wintest" {
metadata {
namespace = "test"
name = "wintest-ingress"
}
spec {
ingress_class_name = "nginx"
rule {
http {
path {
path = "/"
backend {
service {
name = "wintest-svc"
port {
number = 80
}
}
}
}
}
}
}
}
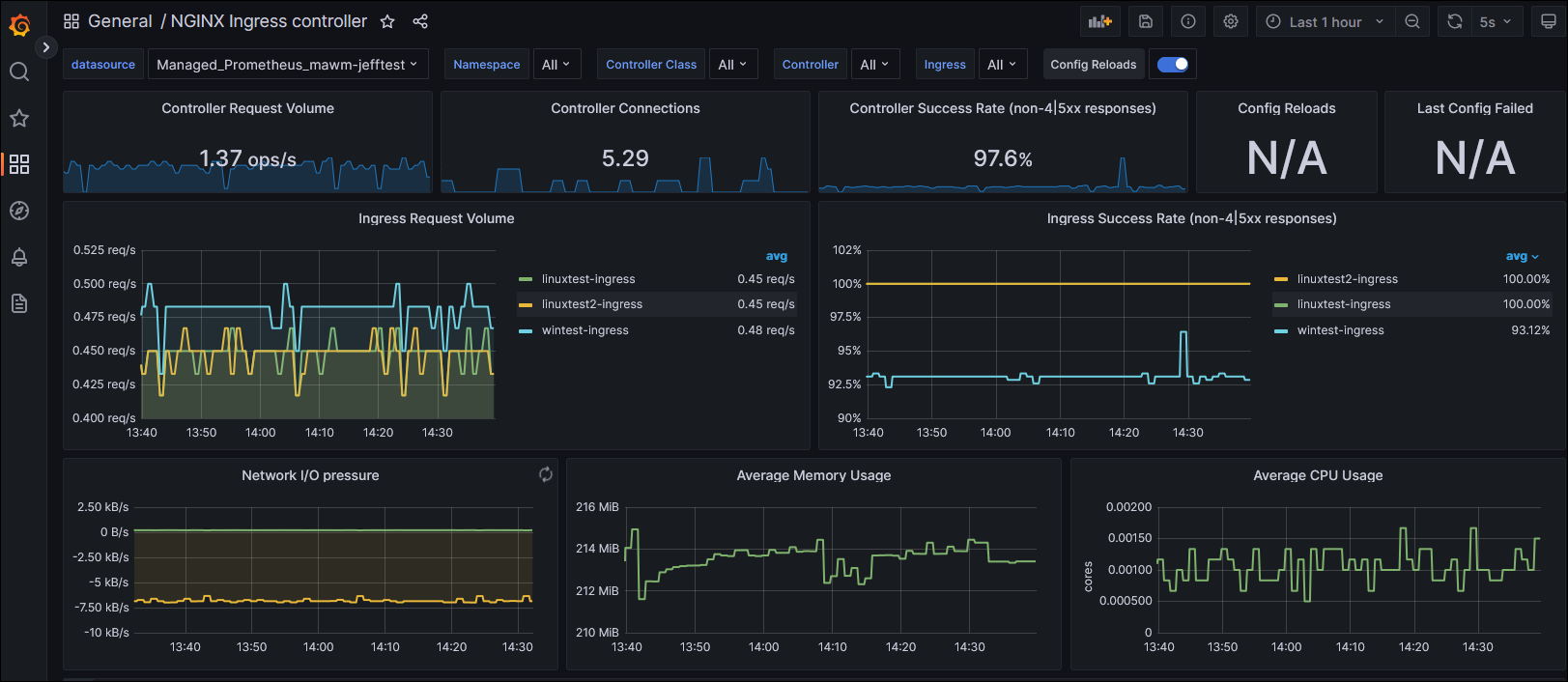
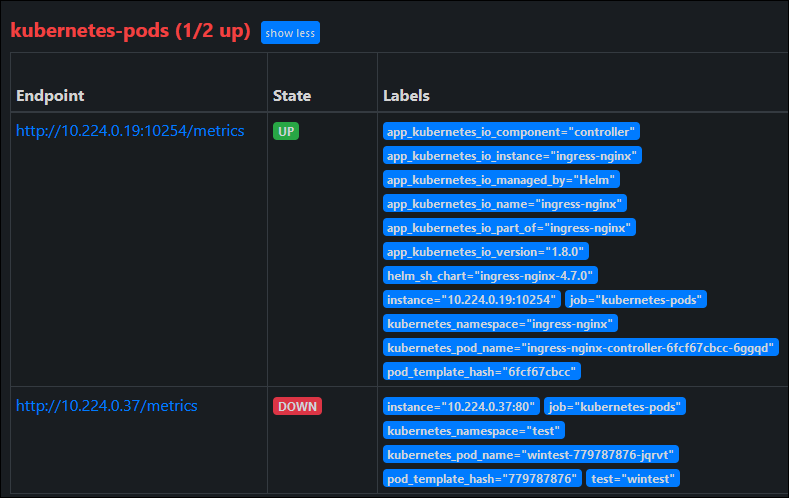
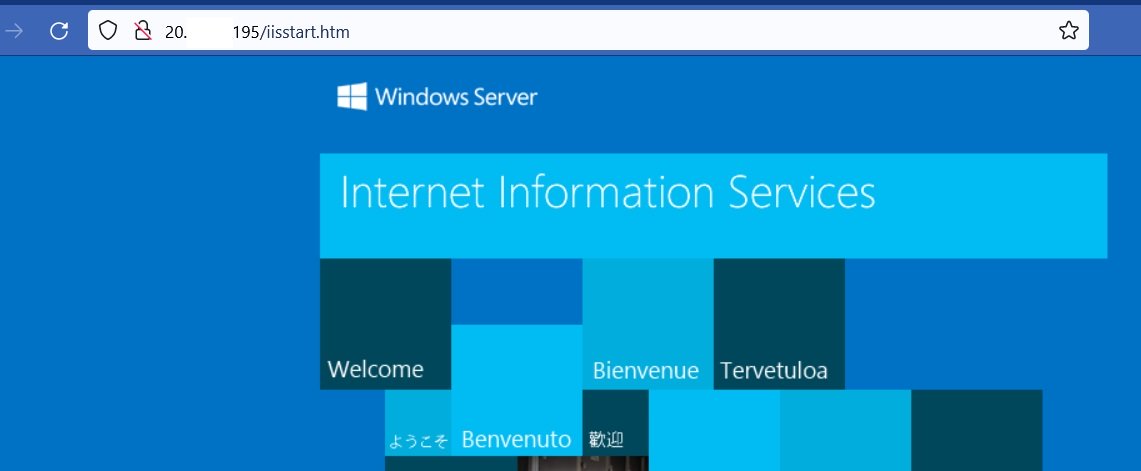
This produces a Deployment of a Windows Server 2022 IIS container, a Service, and in Ingress tied to the ingress-nginx controller that was created through Helm.
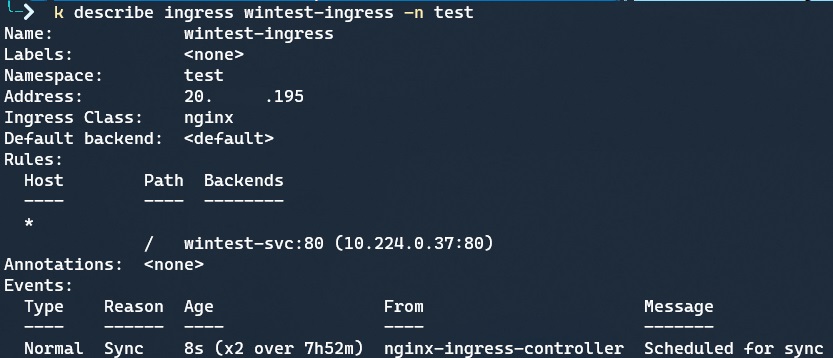
I can connect to my AKS cluster with Azure CLI, kubectl describe my Ingress to view it’s public IP address:
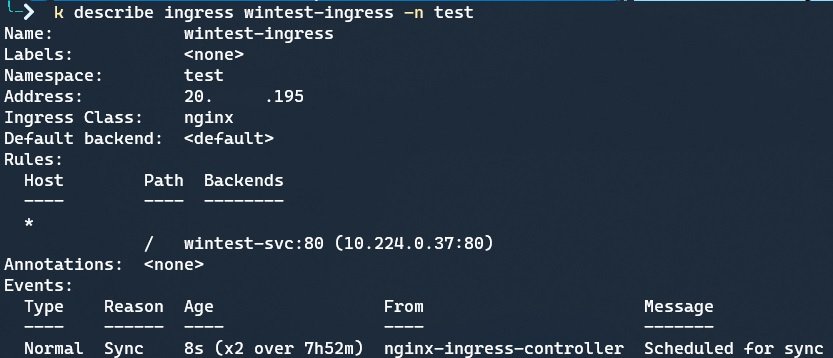
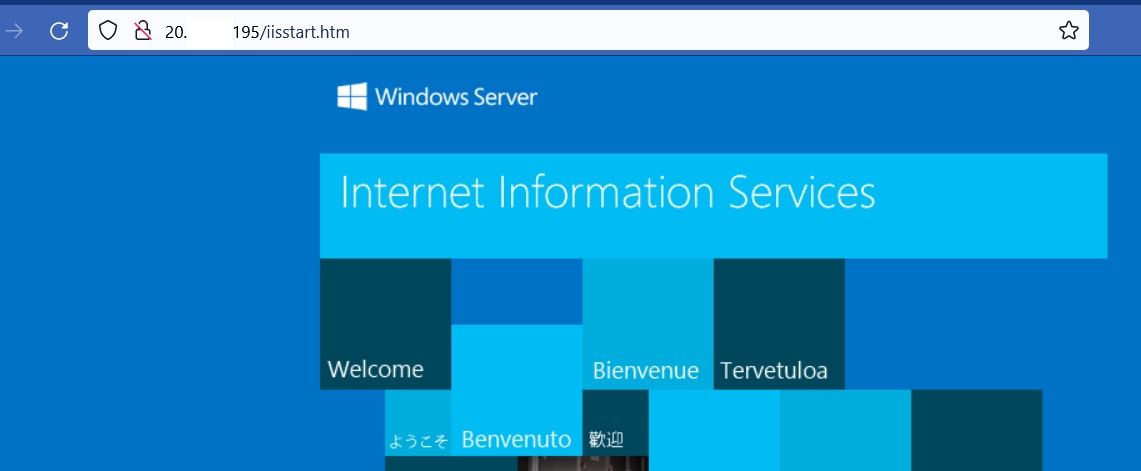
And then hit it in the browser on the “iisstart.htm” page to valid it is working:
Now we’re all set to begin working with the managed services of Prometheus and Grafana, which I’ll dig into in part 2.