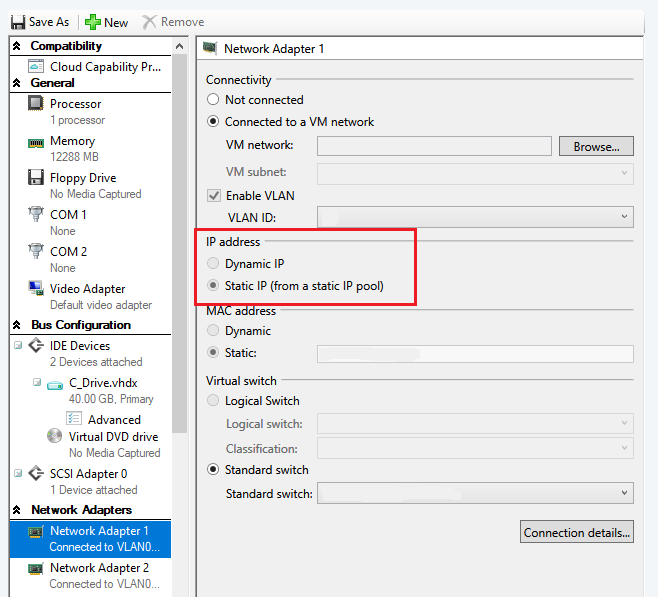
I ran into an issue while setting up a new Hyper-V server in System Center VMM yesterday. I’m using a Switch Independent team on the server, and while I configured it on the host first, I started going down the path of setting up the networking using VMM components, like uplink port profiles and logical switches. At one point I decided to revert back to my original configuration, but I found that my new logical switch had a dependency on my host, despite removing all visible configuration.
The only thing odd about this host that I could see was that on the NIC used for the Hyper-V virtual switch, it was pinned to a logical network and greyed out; I couldn’t remove it:
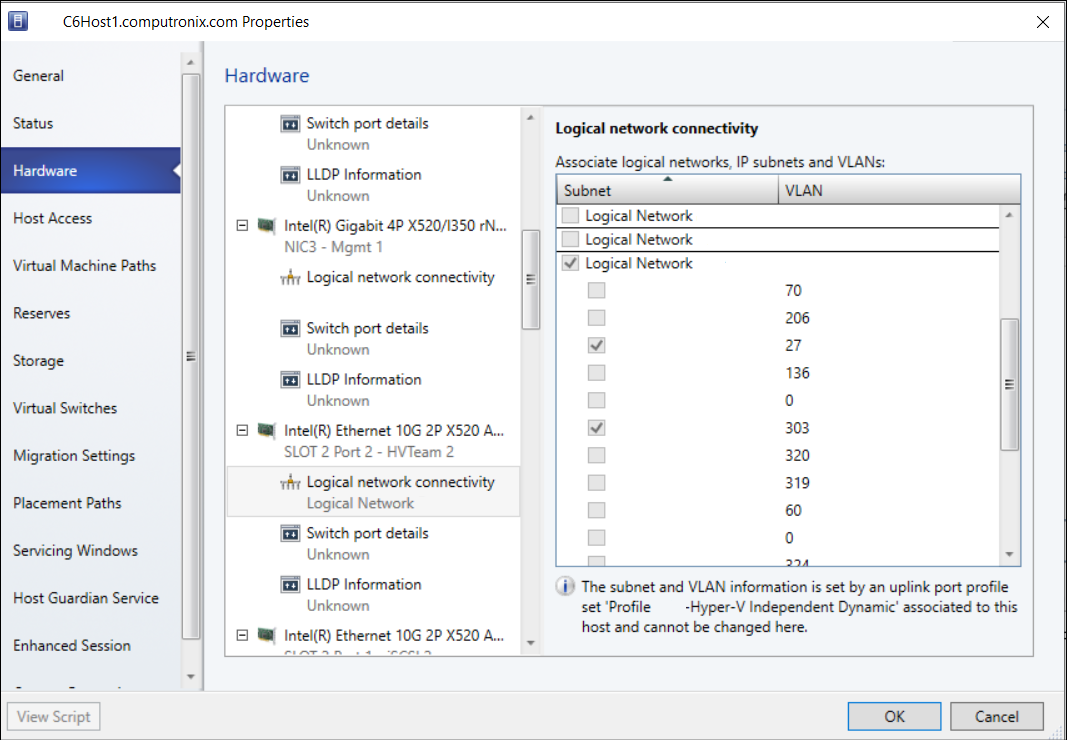
This is a server in a cluster, and the second host didn’t exhibit the same problem. I decided to check off a logical network on a different NIC, and then hit the “View Script” button to see the PowerShell that VMM generated, to try and reverse engineer what was happening.
The PowerShell used the cmdlets “Get-SCVMHost”, “Get-SCVMHostNetworkAdapter”, and “Set-SCVMHostNetworkAdapter”. After following those through, I ended up with a command to remove the logical network from my NIC:
Set-SCVMHostNetworkAdapter -VMHostNetworkAdapter $vmhostnetworkadapter -RemoveLogicalNetwork $logicalNetwork |
However, this produced an error:
Set-SCVMHostNetworkAdapter : The selected host adapter ‘Intel(R) Ethernet 10G 4P X520/I350 rNDC #2$$$Microsoft:{F17CF86F-A125-4EE7-9DB3-0777D9935BA4}’ has an uplink
port profile set configured with network sites, so logical networks, IP subnets, or VLANs cannot be directly modified on the host network adapter. (Error ID: 25234)
When I viewed the dependency on the Uplink Port Profile, it displayed my server name; but I couldn’t see this uplink port profile anywhere in the GUI for the server.
Reviewing the docs on the “Set-SCVMHostNetworkAdapter” led me to another switch: RemoveUplinkPortProfileSet
Here’s the full PowerShell I used to remove this, which allowed me to remove my logical switch and uplink port profile.
$vmHost = Get-SCVMHost -Computername "hostname" #Get-SCVMHostNetworkAdapter -VMHost $vmHost | select name, connectionName # Find the NIC by connectionName, so I can use the real name in the next command $vmHostNetworkAdapter = Get-SCVMHostNetworkAdapter -VMHost $vmHost -name "Intel(R) Ethernet 10G 2P X520 Adapter" $logicalNetwork = Get-SCLogicalNetwork -Name "logical network name" Set-SCVMHostNetworkAdapter -VMHostNetworkAdapter $vmhostnetworkadapter -RemoveUplinkPortProfileSet |