I’m testing some things with Azure Application Gateway this week, and ran into a problem after trying to isolate down a network security group (NSG) to restrict virtual network traffic between subnets and peered VNETs.
Here’s the test layout:
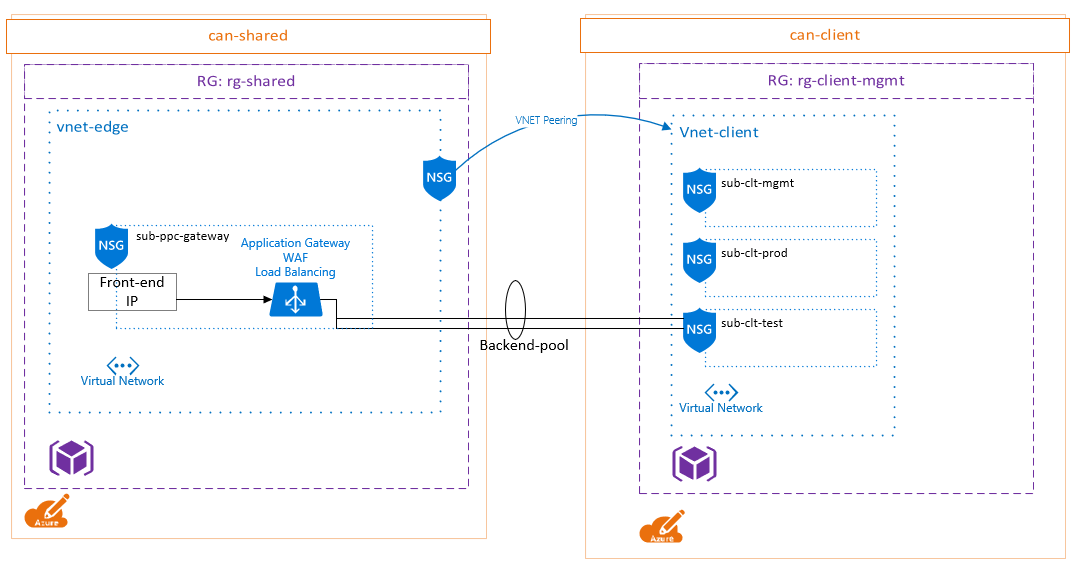
The NSG applied to the “sub-clt-test” has a default incoming rule to allow VirtualNetwork traffic of any port. This is a service tag and according to Microsoft the VirtualNetwork tag includes all subnets within a VNET as well as peered VNETs. This means in my diagram, there’s an “allow all” rule between my “vnet-edge” and “vnet-client”. Not ideal.
I created a new rule on the NSG for “sub-clt-test” to deny all HTTP traffic into the subnet, and then the following intending to allow the Application Gateway to communicate to it’s backend-pool targets:
| Source | Destination | Port |
| 10.8.48.6 | Any | 80 |
| AzureLoadBalancer (Service Tag) | Any | 80 |
The IP address listed there is what is listed as the the frontend private IP of my Application Gateway, within the subnet 10.8.48.0/24. I added the second rule during testing in case that the Microsoft service tag included the Application Gateway within its dynamic range.
What I discovered is that this configuration broke the Application Gateway’s ability to communicate with the backend targets. The health probes went unresponsive and suggested that the NSG is reviewed.
I knew that this wasn’t due to outbound restrictions on any of my NSG’s because as soon as I removed the incoming port 80 deny on this subnet, it began functioning again.
I removed the Deny rule, and then installed WireShark on the backend web server, to collect information about what IP was actually making the connection.
I discovered that while the frontend private IP was listed as 10.8.48.6, it is actually the IP addresses of 10.8.48.4 and 10.8.48.5 making the connection to the backend pool. The frustrating part is that I couldn’t find any explanation for this behavior in Microsoft documentation – I know that the Application Gateway requires its own subnet not to be shared with other resources, but there’s no references to the reserved IP’s that traffic would be coming from.
Since the subnet is effectively reserved for this resource its easy enough to modify my NSG for the range, but I felt like I was missing something obvious as to why it is these IP addresses being used for the connections.
Halfway through writing this post though, I came across this blog post by RoudyBob, with a bit of insight. Each instance of the Application Gateway uses an IP from the subnet assigned, and it is these IPs that will communicate with your backend targets.