I’m working on a specific test case of Azure Site Recovery and came across an error, which identified a gap in my knowledge of ASR and Hyper-V Replica.
I have ASR configured to replicate a group of VMs at 5 minute intervals. My initial replication policy for this proof-of-concept was configured to hold recovery points for 2 hours, with app-consistent snapshots every 1 hour. 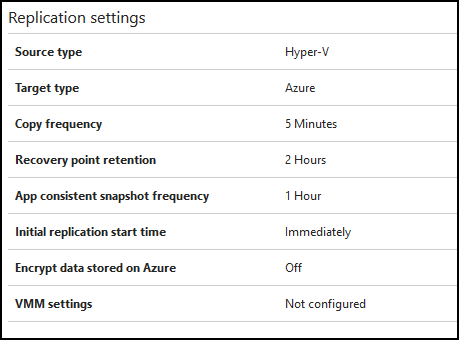
In practice, what I have seen for potential select-able recovery points is one every 5 minutes going back to the latest application-consistent recovery point, and then any additional app-consistent recovery points within the retention time set (2 hours): 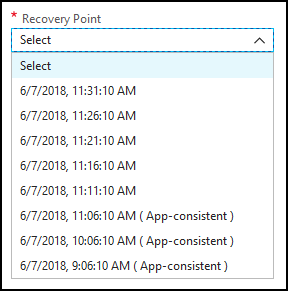
Because the underlying mechanism is Hyper-V Replica, this corresponds to the options for Recovery Points visible in Hyper-V Manager:
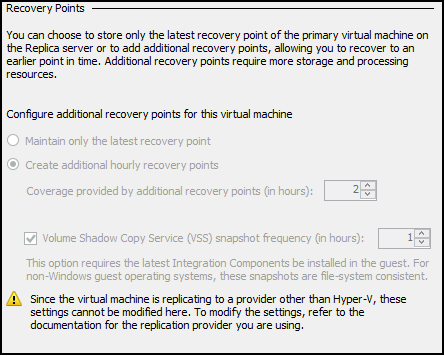
Hyper-V will perform the .HRL file replication to Azure every 5 minutes as configured, but it will also utilize the Hyper-V integration components to trigger in-guest VSS for the application-aware snapshot at 1 hour intervals. This means the RPO in general is up to 5 minutes, but for application-aware RPO it is 1 hour.
In addition to replication, I am backing up a VM with Quest Rapid Recovery. The test was to ensure that both protection methods (Disaster Recovery and Backup) do not conflict with each other. Rapid Recovery is running an incremental snapshot every 20 minutes, and on about 40% of them the following events are received in the Application Log for the VSS service:
Volume Shadow Copy Service error: The I/O writes cannot be flushed during the shadow copy creation period
Volume Shadow Copy Service error: Unexpected error DeviceIoControl(\\?\Volume{a9dca4cb). hr = 0x80070016, The device does not recognize the command.
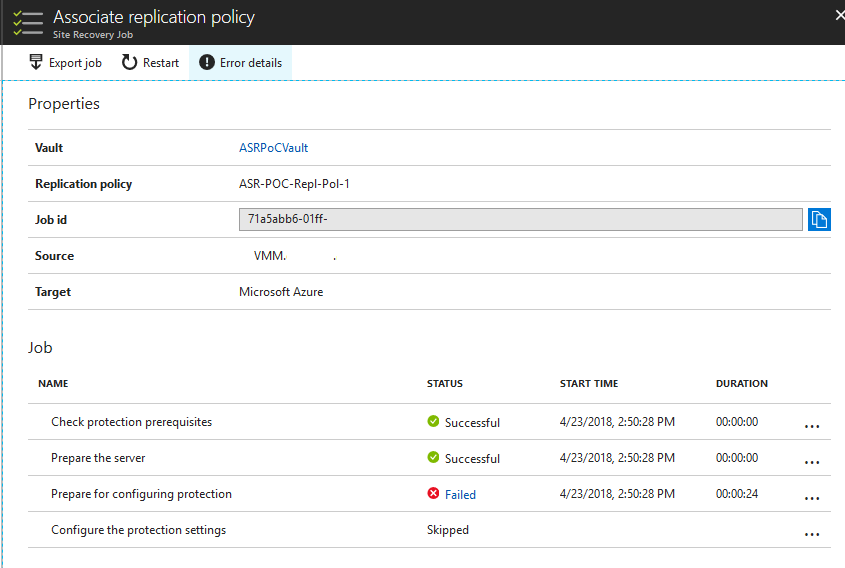
Quest has a KB article about this issue, which says to disable the Hyper-V integration component for backup in order to avoid a timing conflict when the host uses the Volume Shadow Copy requestor service. The problem is, disabling this prevents ASR from getting an application-aware snapshot of the virtual machine, which it will begin to throw warnings about after a few missed intervals:
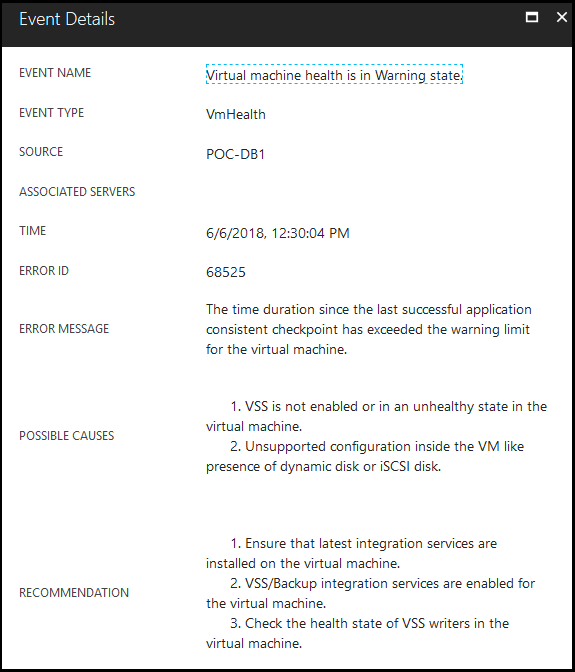
These problems make sense though – for every hourly attempt of Hyper-V to take an application-aware snapshot using VSS, Rapid Recovery finds that writer in use and times-out waiting for it. There isn’t a way to configure when in an hour Hyper-V takes the snapshot, but I’ve begun tweaking my Rapid Recovery schedule to not occur on rounded intervals like :00 or :10, but rather :03 or :23 in an attempt to avoid conflicts with the VSS timing. So far this hasn’t been as effective as I’d hoped.
The other alternative is to disable application-aware snapshots if they’re not needed. If it is just flat files or an application that doesn’t natively tie into VSS, the best you can expect is a crash-consistent snapshot and you should configure your ASR replication policy accordingly, by setting that value to 0. In this manner you can still retain multiple hours of recovery points, they’ll just ALL be crash-consistent.