I deepened my understanding of Azure outbound Internet connections today. I’ve been working on setting up an outbound proxy using Squid, and just struggling with connectivity. I want my outbound proxy to be highly available, so I thought, “I’ll put it into a Load Balancer, and I want the Standard SKU”. As soon as I did this, my proxy stopped working.
I banged my head against that problem for an hour or two, and then came back to it another day, read the docs, and had a breakthrough in understanding.
Setup
Here’s the resource layout I’m working with:
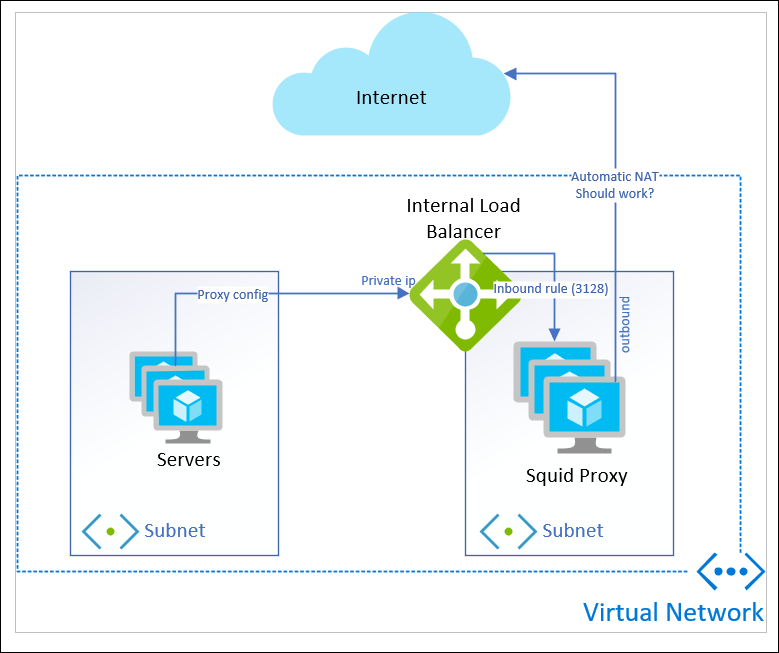
I have a bunch of servers in a subnet. They use WPAD dns resolution to direct Internet traffic to the Private IP address of a load balancer, sitting in a different subnet.
Two Linux VMs in an availability set are the back-end of my load balancer. I use an inbound rule for port 3128 to receive the proxy traffic.
The outbound line to the Internet is what I assumed would happen: I’ve read through “Outbound Connections in Azure” a few times and thought I had a handle on what would occur.
The Problem
It didn’t work! As soon as I put my Squid VMs into the load balancer, they stopped being able to proxy traffic. So I thought, “lets put it in a Basic load balancer, it’d be cheaper anyway”. And that worked! At this time I didn’t really understand what was going on, and knew I needed to come back to it after some sleep.
The Discovery
Lets take a closer look at the Microsoft Doc I just linked above. There are 3 outbound scenarios it describes:
- VM with an Instance Level Public IP address (with or without Load Balancer)
- Not my scenario – I don’t have Public IP address attached to my Squid VMs
- Public Load Balancer associated with a VM (no Public IP address on the instance)
- Not my scenario – I’m using an Internal load balancer, not a Public one.
- Standalone VM (no Load Balancer, no Public IP address)
- This is what I thought the behavior would default to – use a dynamic public IP from Azure pool and SNAT outbound traffic
In the detail of Scenario 3, the first sentence says “In this scenario, the VM is not part of a public Load Balancer pool (and not part of an internal Standard Load Balancer pool) and does not have a Public IP address assigned to it.”
Well, I am part of an Internal Standard Load Balancer pool; where does that leave me?
The blue box just below makes it very clear:

Scenario #3 is NOT a fail-back option when using an Internal load balancer of Standard SKU.
Later on in the document, this is made more explicit:
"When using an internal Standard Load Balancer, outbound NAT is not available until outbound connectivity has been explicitly declared."
Scenario #3 IS the fail-back option when using an Internal Basic load balancer, which I think was the source of my assumption. This is why I can get Internet connectivity when I place my Squid VM into the back-end of a basic load balancer. The major downside of this is I cannot control the IP address my proxy communicates outbound on, which is a firm requirement for me.
I verified this problem and scenario #1 resolution: from my VM I used a ‘wget’ command while operating under my original design – it timed out:

Then I added a public IP address to one VM, and performed the same test:
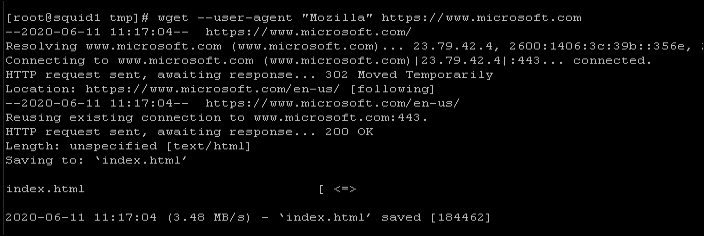
The Solution
As the doc describes, there are a few solutions although at the time of this writing it is missing one.
- add Public IP to each VM
- add a public load balancer, create outbound rules, and add the squid as backend to it
- add NAT gateway to the subnet
add Public IP to each VM
I can create a public IP address for each VM and associate it.
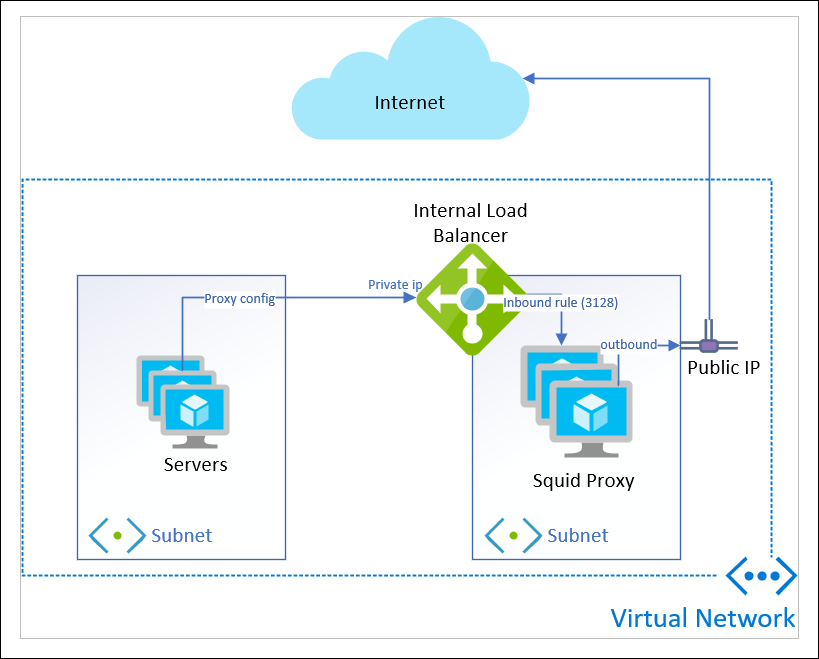
This will give me static IP addresses, but I have to do it for each VM in the back-end.
Each static Standard IP is 0.005/hour ($3.65 USD/mo).
Lets say I am transferring 100GB/mo outbound between the two VMs. Bandwidth is 95 GB (first 5 GB free) at $0.087/GB so $8.265 USD / mo.
Total cost = $15.565 USD / month
add a public load balancer, create outbound rules, and add the squid as backend to it
Turns out you can have the same VMs be back-ends to BOTH a public and an internal Standard load balancer at the same time.
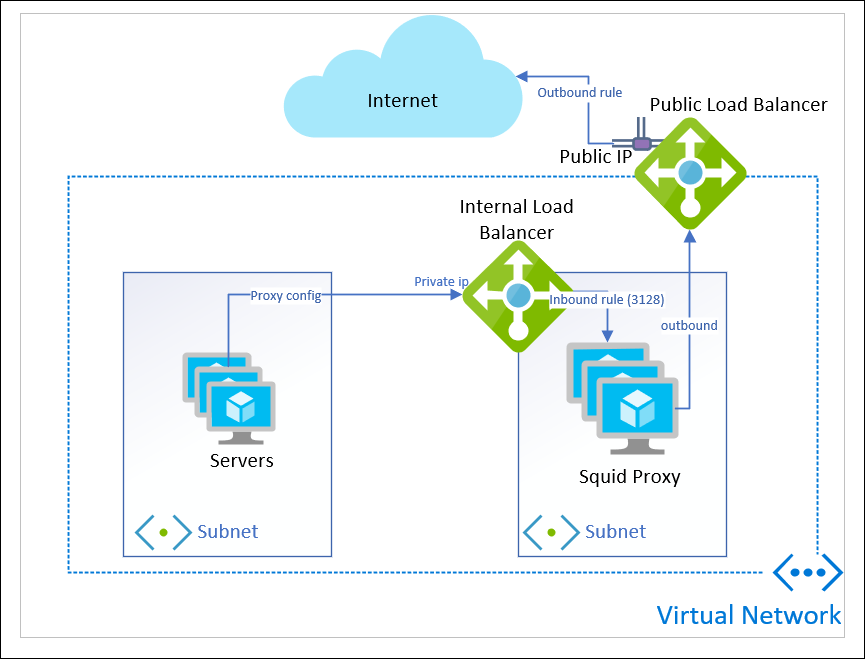
This gives some flexibility, because now you can scale out in the backend, as long as you pay attention to the scaling guidelines from Microsoft and avoid SNAT port exhaustion.
You can apply only an Outbound rule (you must apply this) so that it acts only as outbound load balancer, and not in-bound.
Single public IP cost of $3.65 USD/mo still applies.
Standard Load Balancer with a small number of rules (first 5 are free) processing 100GB of traffic is $18.75 USD/mo.
We still need to pay the bandwidth charge since we have traffic egress to Internet: $8.265 USD / mo
Total cost: $27.015 USD / month
add NAT gateway to the subnet
A new feature of Azure that recently went GA is NAT Gateway (or Virtual Network NAT). This provides outbound connectivity for an entire subnet, rather than at a VM level.
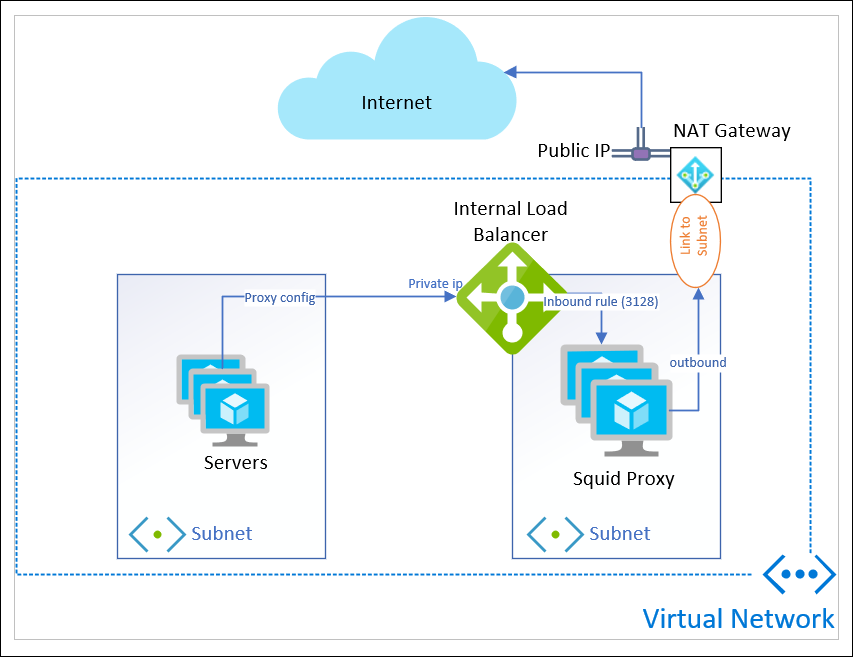
Important to note, a NAT Gateway CANNOT be linked to a subnet that contains any Basic IP addresses, or Basic load balancers.
This simplifies beyond the outbound public load balancer; you can still attach to a public IP address, but do not need to manage individual outbound rules and backend pools.
If there are other resources in the subnet, they too can take advantage of the NAT Gateway and a static public IP address.
Single public IP cost of $3.65 USD/mo still applies.
It doesn’t seem like the NAT Gateway is integrated into the Pricing Calculator yet, but the Docs page has a section on Pricing:
- Resource hours $0.045/hour * 730 = $32.85 USD / mo
- Data processed $0.045/GB * 100GB = $4.5 USD / mo
We still need to pay the bandwidth charge since we have traffic egress to Internet: $8.265 USD / mo
Total cost: $49.265 USD / month