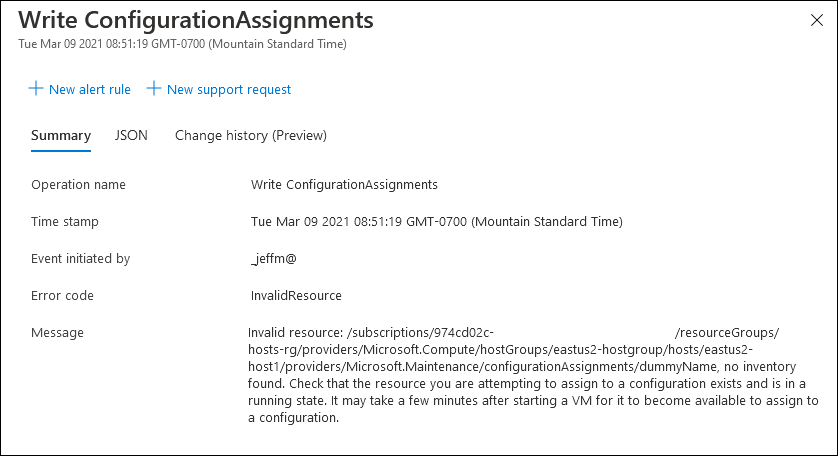
A co-worker recently posed a question to me regarding virtual machines in Azure – “how do they activate Windows?”
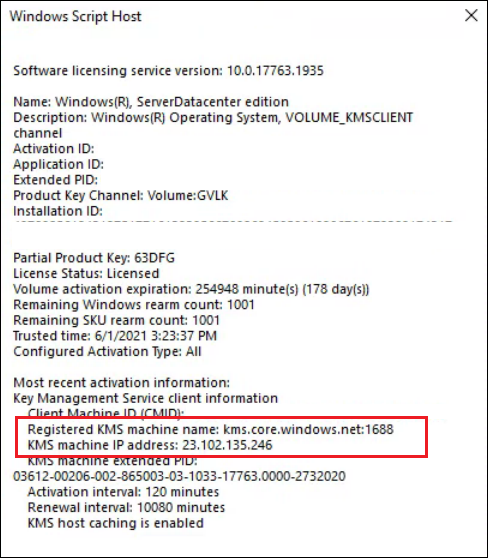
The short answer is through KMS – using a KMS key and “kms.core.windows.net:1688”. You can see this on an Azure VM by typing:
slmgr /dlv
The functionality of KMS within Azure isn’t well documented, but there are buried references to things like:
The IP address of the KMS server for the Azure Global cloud is 23.102.135.246. Its DNS name is kms.core.windows.net.
This is a singular IP used globally, and from that same doc, “requires that the activation request come from an Azure public IP address.”
This leads to another question – “In an environment with deny-by-default outbound rules, how does KMS communicate?”
The short answer here is, “Magic?”
Lets say I have an NSG attached to a subnet, with the following outbound rules:
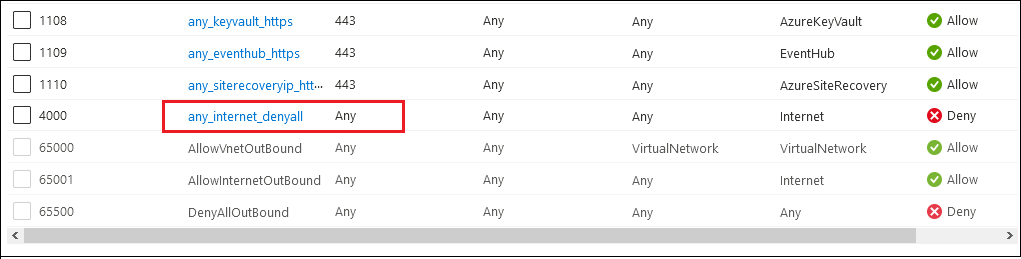
There is nothing specifically allowing access to the “kms.core.windows.net” IP address, but there IS a deny rule to the Internet Service Tag, so I would expect this traffic to be denied.
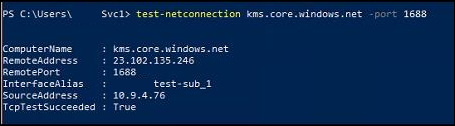
But a Test-NetConnection succeeds!
I check Network Watcher, with the IP Flow Verify tool. It says that this traffic will be denied by my Internet deny rule.
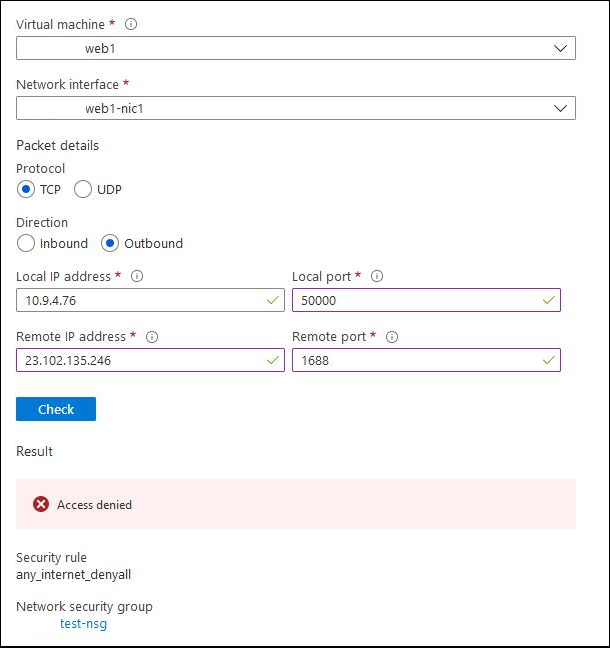
I check the NSG Flow Logs, and surprisingly I see zero references to my traffic on ANY rules! But, if I change my Test-NetConnection to a different port (say 1687), then it does appear as denied:
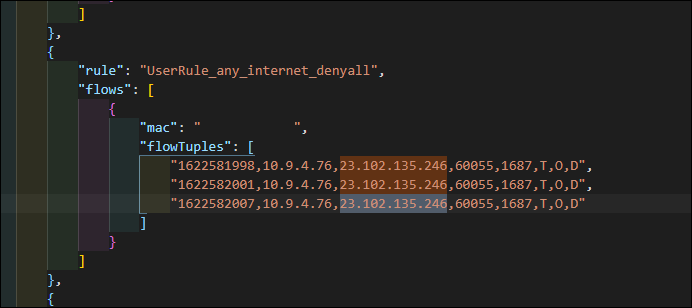
What is happening here?
I have yet to find anything authoritative in Microsoft’s documentation or any related GitHub issue. But based on what has been tested and the existing documents, I think that there is a hidden default NSG rule (likely below priority 100) which is configured to not be visible or logged (even from Network Watcher!) but allows traffic despite my own best efforts to block it.
This is operating effectively the same way that Azure DNS does, I believe – the IP address 168.63.129.16 is always reachable, regardless of the NSG rules you put in place.
There can be exceptions to that statement – there is a Service Tag named AzurePlatformLKM, which can be used to “disable the defaults for licensing” – I believe (but haven’t yet tested) that using this Service Tag in a deny rule would effectively block this traffic on 1688.