While working on a design for virtual machine placement in Azure, I got to wondering about specifics of Availability Zones and the potential performance impacts of not actually choosing one. My findings below are a little bit conjecture at this point, not having found direct confirmation from Microsoft on the topic.
Availability Zones are a method within Azure to provide resiliency for resources by using multiple datacenters within a region.
Resources within Azure can be one of 3 types related to these zones:
- Zonal services – where a resource is pinned to a specific zone (for example, virtual machines, managed disks, Standard IP addresses), or
- Zone-redundant services – when the Azure platform replicates automatically across zones (for example, zone-redundant storage, SQL Database).
- None – not actually documented (yet?) but this is the type when you have a Zonal service but do not select a zone.
The last item there is of particular interest – if you don’t select a zone for a Zonal service, where does it go? This issue from Microsoft Docs has a description of an “allocator” that works behind the scenes to make a decision on zone placement, but that is never surfaces to you; not even available in the Azure Resource Explorer.
For example, here’s a snipped of the metadata available for a VM with a specific Zone placement:
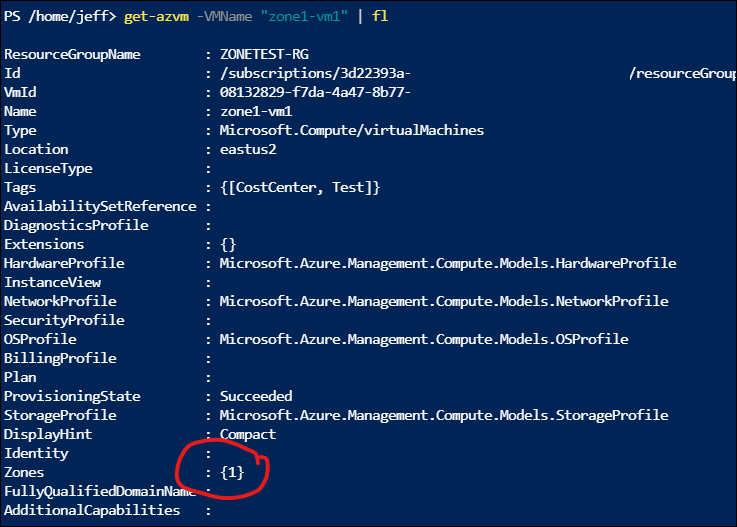
And here’s one without any at all:
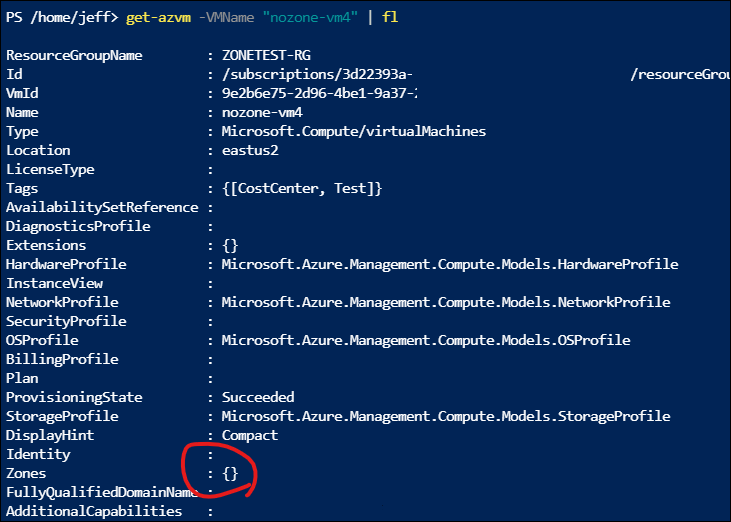
This led to some questions for me:
- Am I losing performance (higher latency) by not setting my VMs in the same zone (if they happen to be placed in separate zones by the “allocator”)?
- Will I be charged for bandwidth between zones when billing begins on July 1, 2021 for it, if my VMs don’t have a zone selected but get placed in separate zones?
I’ve asked #2 in an Issue on the doc, and hopefully will receive an answer. I set out to test #1 within EastUS2.
Starting with Microsoft’s recommendation for latency testing on a virtual network, I downloaded the “latte.exe” tool and spun up some VMs.
The advantage of this tool, according to Microsoft, is:
latte.exe (for Windows) can isolate and measure network latency while excluding other types of latency, such as application latency.
Other common connectivity tools, such as Ping … employ the Internet Control Message Protocol (ICMP), which can be treated differently from application traffic and whose results might not apply to workloads that use TCP and UDP.
The output of this tool looks like this, and it is the Latency value we’re after:
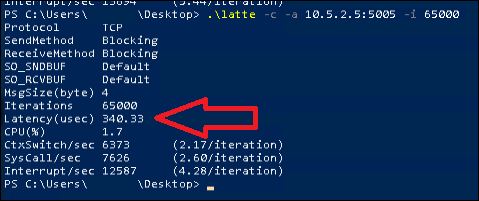
While running multiple tests on idle VMs, I found a discrepancy of ~20-30 us between tests, so take that into account when viewing the results below.
Here’s some of the results that I found:
| Test | Result (us) |
|---|---|
| 2 VMs, same availability zone, accelerated networking is false: | 340 |
| 2 VMs, same availability zone, accelerated networking is true: | 169 |
| 2 VMs, different availability zone, accelerated networking is false: | 397 |
| 2 VMs, different availability zone, accelerated networking is true: | 150 |
| 2 VMs, no availability zone selected, accelerated networking is false: | 427 |
| 2 VMs, no availability zone selected, accelerated networking is true: | 144 |
| 2 VMs, same availability zone, accelerated networking is true, proximity placement group aligned: | 158 |
It doesn’t seem right, but the conclusion that I draw from this is that the latency between availability zones (at least in EastUS2) is functionally equivalent to within a zone, and even within a proximity placement group, which is supposed to improve even more.
I don’t have a good explanation for these results yet – perhaps my testing is flawed in some way, or perhaps this is specific to EastUS2 and the differences are more varied in other Regions where the datacenters are further apart, or consist of more datacenters within each zone itself.