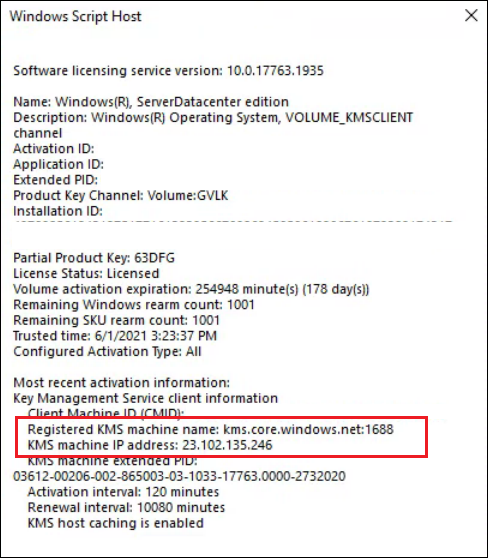
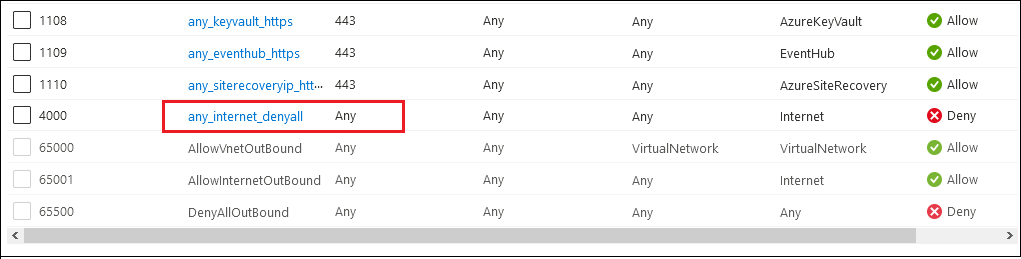
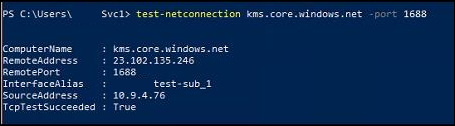
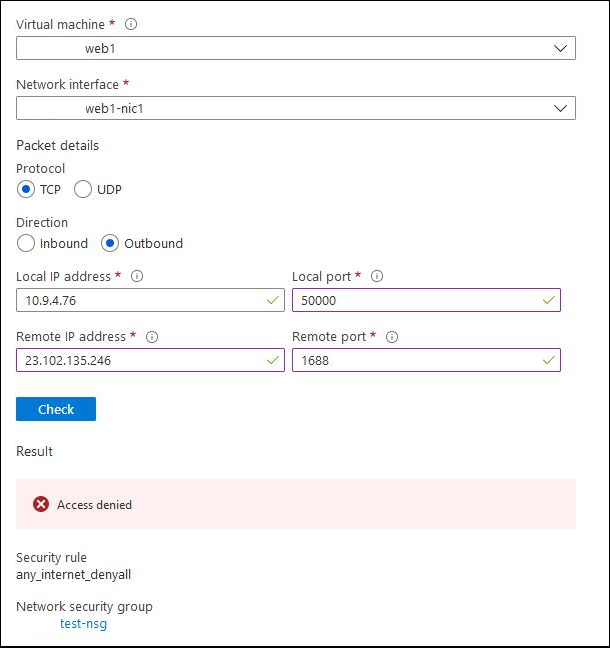
A situation came up where I needed to have two HTTP bindings on port 80 on a web server residing in Azure. This would be 1 binding each on two different IIS sites within a single VM. The creation of this configuration isn’t as simple as one would initially expect, due to some Azure limitations.
There are two options in order to achieve this:
- Add a secondary virtual network interface to the VM
- Add a second static IP configuration on the primary virtual network interface of the VM.
For each of these, I wanted to deploy the necessary configuration through Terraform and Desired State Configuration (DSC).
Second IP Configuration
In this scenario, its quite simple to add a second static IP configuration in terraform:
resource "azurerm_network_interface" "testnic" {
name = "testnic"
location = "${var.location}"
resource_group_name = "${azurerm_resource_group.test.name}"
ip_configuration {
name = "ipconfig1"
subnet_id = "${azurerm_subnet.test.id}"
private_ip_address_allocation = "static"
private_ip_address = "10.2.0.5"
primary = true
}
ip_configuration {
name = "ipconfig2"
subnet_id = "${azurerm_subnet.test.id}"
private_ip_address_allocation = "static"
private_ip_address = "10.2.0.6"
}
} |
resource "azurerm_network_interface" "testnic" {
name = "testnic"
location = "${var.location}"
resource_group_name = "${azurerm_resource_group.test.name}"
ip_configuration {
name = "ipconfig1"
subnet_id = "${azurerm_subnet.test.id}"
private_ip_address_allocation = "static"
private_ip_address = "10.2.0.5"
primary = true
}
ip_configuration {
name = "ipconfig2"
subnet_id = "${azurerm_subnet.test.id}"
private_ip_address_allocation = "static"
private_ip_address = "10.2.0.6"
}
}
However, when using static IP addresses like this, Azure requires you to perform configuration within the VM as well. This is necessary for both the primary IP configuration, as well as the secondary.
Here’s how you can configure it within DSC:
Configuration dsctest
{
Import-DscResource -ModuleName PSDesiredStateConfiguration
Import-DscResource -ModuleName xPSDesiredStateConfiguration
Import-DscResource -moduleName NetworkingDSC
Node localhost {
## Rename VMNic
NetAdapterName RenameNetAdapter
{
NewName = "PrimaryNIC"
Status = "Up"
InterfaceNumber = 1
}
DhcpClient DisabledDhcpClient
{
State = 'Disabled'
InterfaceAlias = 'PrimaryNIC'
AddressFamily = 'IPv4'
DependsOn = "[NetAdapterName]RenameNetAdapter "
}
IPAddress NewIPv4Address
{
#Multiple IPs can be comma delimited like this
IPAddress = '10.2.0.5/24','10.2.0.6/24'
InterfaceAlias = 'PrimaryNIC'
AddressFamily = 'IPV4'
DependsOn = "[NetAdapterName]RenameNetAdapter "
}
# Skip as source on secondary IP address, in order to prevent DNS registration of this second IP
IPAddressOption SetSkipAsSource
{
IPAddress = '10.2.0.6'
SkipAsSource = $true
DependsOn = "[IPAddress]NewIPv4Address"
}
DefaultGatewayAddress SetDefaultGateway
{
Address = '10.2.0.1'
InterfaceAlias = 'PrimaryNIC'
AddressFamily = 'IPv4'
}
}
} |
Configuration dsctest
{
Import-DscResource -ModuleName PSDesiredStateConfiguration
Import-DscResource -ModuleName xPSDesiredStateConfiguration
Import-DscResource -moduleName NetworkingDSC
Node localhost {
## Rename VMNic
NetAdapterName RenameNetAdapter
{
NewName = "PrimaryNIC"
Status = "Up"
InterfaceNumber = 1
}
DhcpClient DisabledDhcpClient
{
State = 'Disabled'
InterfaceAlias = 'PrimaryNIC'
AddressFamily = 'IPv4'
DependsOn = "[NetAdapterName]RenameNetAdapter "
}
IPAddress NewIPv4Address
{
#Multiple IPs can be comma delimited like this
IPAddress = '10.2.0.5/24','10.2.0.6/24'
InterfaceAlias = 'PrimaryNIC'
AddressFamily = 'IPV4'
DependsOn = "[NetAdapterName]RenameNetAdapter "
}
# Skip as source on secondary IP address, in order to prevent DNS registration of this second IP
IPAddressOption SetSkipAsSource
{
IPAddress = '10.2.0.6'
SkipAsSource = $true
DependsOn = "[IPAddress]NewIPv4Address"
}
DefaultGatewayAddress SetDefaultGateway
{
Address = '10.2.0.1'
InterfaceAlias = 'PrimaryNIC'
AddressFamily = 'IPv4'
}
}
}
Both the disable DHCP and DefaultGateway resources are required, otherwise you will lose connectivity to your VM.
Once the “SkipAsSource” runs, this sets the proper priority for the IP addresses, matching the Azure configuration.
Second NIC
When adding a second NIC in Terraform, you have to add a property (“primary_network_interface_id”) on the VM resource for specifying the primary NIC.
resource "azurerm_network_interface" "testnic1" {
name = "testnic"
location = "${var.location}"
resource_group_name = "${azurerm_resource_group.test.name}"
ip_configuration {
name = "ipconfig1"
subnet_id = "${azurerm_subnet.test.id}"
private_ip_address_allocation = "static"
private_ip_address = "10.2.0.5"
}
}
resource "azurerm_network_interface" "testnic2" {
name = "testnic"
location = "${var.location}"
resource_group_name = "${azurerm_resource_group.test.name}"
ip_configuration {
name = "ipconfig1"
subnet_id = "${azurerm_subnet.test.id}"
private_ip_address_allocation = "static"
private_ip_address = "10.2.0.6"
}
}
resource "azurerm_virtual_machine" "test" {
name = "helloworld"
location = "${var.location}"
resource_group_name = "${azurerm_resource_group.test.name}"
network_interface_ids = ["${azurerm_network_interface.testnic1.id}","${azurerm_network_interface.testnic2.id}"]
primary_network_interface_id = "${azurerm_network_interface.test.id}"
vm_size = "Standard_A1"
storage_image_reference {
publisher = "MicrosoftWindowsServer"
offer = "WindowsServer"
sku = "2016-Datacenter"
version = "latest"
}
storage_os_disk {
name = "myosdisk1"
vhd_uri = "${azurerm_storage_account.test.primary_blob_endpoint}${azurerm_storage_container.test.name}/myosdisk1.vhd"
caching = "ReadWrite"
create_option = "FromImage"
}
os_profile {
computer_name = "helloworld"
admin_username = "${var.username}"
admin_password = "${var.password}"
}
os_profile_windows_config {
provision_vm_agent = true
enable_automatic_upgrades = true
}
} |
resource "azurerm_network_interface" "testnic1" {
name = "testnic"
location = "${var.location}"
resource_group_name = "${azurerm_resource_group.test.name}"
ip_configuration {
name = "ipconfig1"
subnet_id = "${azurerm_subnet.test.id}"
private_ip_address_allocation = "static"
private_ip_address = "10.2.0.5"
}
}
resource "azurerm_network_interface" "testnic2" {
name = "testnic"
location = "${var.location}"
resource_group_name = "${azurerm_resource_group.test.name}"
ip_configuration {
name = "ipconfig1"
subnet_id = "${azurerm_subnet.test.id}"
private_ip_address_allocation = "static"
private_ip_address = "10.2.0.6"
}
}
resource "azurerm_virtual_machine" "test" {
name = "helloworld"
location = "${var.location}"
resource_group_name = "${azurerm_resource_group.test.name}"
network_interface_ids = ["${azurerm_network_interface.testnic1.id}","${azurerm_network_interface.testnic2.id}"]
primary_network_interface_id = "${azurerm_network_interface.test.id}"
vm_size = "Standard_A1"
storage_image_reference {
publisher = "MicrosoftWindowsServer"
offer = "WindowsServer"
sku = "2016-Datacenter"
version = "latest"
}
storage_os_disk {
name = "myosdisk1"
vhd_uri = "${azurerm_storage_account.test.primary_blob_endpoint}${azurerm_storage_container.test.name}/myosdisk1.vhd"
caching = "ReadWrite"
create_option = "FromImage"
}
os_profile {
computer_name = "helloworld"
admin_username = "${var.username}"
admin_password = "${var.password}"
}
os_profile_windows_config {
provision_vm_agent = true
enable_automatic_upgrades = true
}
}
In this scenario, once again Azure requires additional configuration for this to work. The secondary NIC does not get a default gateway and cannot communicate out of it’s subnet.
One way to solve this with DSC is to apply a default route for that interface, with a higher metric than the primary interface. In this case, we don’t need to specify static IP addresses inside the OS through DSC, since there’s only one per virtual NIC.
Configuration dsctest
{
Import-DscResource -ModuleName PSDesiredStateConfiguration
Import-DscResource -ModuleName xPSDesiredStateConfiguration
Import-DscResource -moduleName NetworkingDSC
Node localhost {
## Rename VMNic(s)
NetAdapterName RenameNetAdapter
{
NewName = "PrimaryNIC"
Status = "Up"
InterfaceNumber = 1
Name = "Ethernet 2"
}
NetAdapterName RenameNetAdapter_apps
{
NewName = "SecondaryNIC"
Status = "Up"
InterfaceNumber = 2
Name = "Ethernet 3"
}
Route NetRoute1
{
Ensure = 'Present'
InterfaceAlias = 'SecondaryNIC'
AddressFamily = 'IPv4'
DestinationPrefix = '0.0.0.0'
NextHop = '10.2.0.1'
RouteMetric = 200
}
}
} |
Configuration dsctest
{
Import-DscResource -ModuleName PSDesiredStateConfiguration
Import-DscResource -ModuleName xPSDesiredStateConfiguration
Import-DscResource -moduleName NetworkingDSC
Node localhost {
## Rename VMNic(s)
NetAdapterName RenameNetAdapter
{
NewName = "PrimaryNIC"
Status = "Up"
InterfaceNumber = 1
Name = "Ethernet 2"
}
NetAdapterName RenameNetAdapter_apps
{
NewName = "SecondaryNIC"
Status = "Up"
InterfaceNumber = 2
Name = "Ethernet 3"
}
Route NetRoute1
{
Ensure = 'Present'
InterfaceAlias = 'SecondaryNIC'
AddressFamily = 'IPv4'
DestinationPrefix = '0.0.0.0'
NextHop = '10.2.0.1'
RouteMetric = 200
}
}
}
You could also add a Default Gateway resource to the second NIC, although I haven’t specifically tested that.
Generally speaking, I’d rather add a second IP to a single NIC – having two NICs on the same subnet with the same effective default gateway might function, but doesn’t seem to be best practice to me.